1774597379
@@ -1,53 +1,177 @@
|
|||||||
{
|
{
|
||||||
"recentFiles": [
|
"recentFiles": [
|
||||||
{
|
{
|
||||||
"basename": "20260324090682",
|
"basename": "x-csrf-token",
|
||||||
"path": "000-Inbox/20260324090682.md"
|
"path": "000-inbox/x-csrf-token.md"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"basename": "Docker 核心知识与实战笔记",
|
"basename": "需求-命中率计算",
|
||||||
"path": "000-inbox/Docker 核心知识与实战笔记.md"
|
"path": "000-inbox/需求-命中率计算.md"
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260324085410",
|
|
||||||
"path": "000-Inbox/20260324085410.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260324085466",
|
|
||||||
"path": "000-Inbox/20260324085466.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260324084778",
|
|
||||||
"path": "000-Inbox/20260324084778.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "开发笔记",
|
|
||||||
"path": "work/移动杭研/开发记录/7.18.0/开发笔记.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "tg-bot",
|
|
||||||
"path": "000-inbox/tg-bot.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "0323-邮件发送异常",
|
|
||||||
"path": "work/移动杭研/问题处理/2026-03/0323-邮件发送异常.md"
|
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"basename": "如何成为一个 React 工程师呢?",
|
"basename": "如何成为一个 React 工程师呢?",
|
||||||
"path": "resource/前端/如何成为一个 React 工程师呢?.md"
|
"path": "resource/前端/如何成为一个 React 工程师呢?.md"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260327113359",
|
||||||
|
"path": "000-Inbox/20260327113359.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260327105648",
|
||||||
|
"path": "000-Inbox/20260327105648.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260327101490",
|
||||||
|
"path": "000-Inbox/20260327101490.md"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"basename": "开发笔记",
|
"basename": "开发笔记",
|
||||||
"path": "work/移动杭研/开发记录/7.19.0/开发笔记.md"
|
"path": "work/移动杭研/开发记录/7.19.0/开发笔记.md"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"basename": "TG 备忘录",
|
"basename": "结构化输出和工具调用",
|
||||||
"path": "personal/TG 备忘录.md"
|
"path": "000-inbox/结构化输出和工具调用.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "jinja",
|
||||||
|
"path": "000-inbox/jinja.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "Qwen3.5(通义千问 3.5)系列的多模态图文大模型(Vision-Language Models)",
|
||||||
|
"path": "resource/ai/大模型安装笔记/Qwen3.5(通义千问 3.5)系列的多模态图文大模型(Vision-Language Models).md"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"basename": "IBS 智能体具体落实技术方案",
|
"basename": "IBS 智能体具体落实技术方案",
|
||||||
"path": "work/移动杭研/AI 项目/IBS 智能体具体落实技术方案.md"
|
"path": "work/移动杭研/AI 项目/IBS 智能体具体落实技术方案.md"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260327091590",
|
||||||
|
"path": "000-Inbox/20260327091590.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260327083230",
|
||||||
|
"path": "000-Inbox/20260327083230.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260326175860",
|
||||||
|
"path": "000-Inbox/20260326175860.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "001 大模型启动流程",
|
||||||
|
"path": "resource/ai/大模型安装笔记/001 大模型启动流程.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260326173620",
|
||||||
|
"path": "000-Inbox/20260326173620.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "关于模型思考问题",
|
||||||
|
"path": "resource/ai/大模型安装笔记/关于模型思考问题.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "大模型中的参数、权重与数值类型整理",
|
||||||
|
"path": "resource/ai/大模型安装笔记/大模型中的参数、权重与数值类型整理.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "LLM 三件套",
|
||||||
|
"path": "resource/ai/大模型安装笔记/LLM 三件套.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "000 autodl 机器信息",
|
||||||
|
"path": "resource/ai/大模型安装笔记/000 autodl 机器信息.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "函数调用 和 工具调用",
|
||||||
|
"path": "resource/ai/大模型安装笔记/函数调用 和 工具调用.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "GNU Screen 命令全解析",
|
||||||
|
"path": "000-inbox/GNU Screen 命令全解析.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "Docker 核心知识与实战笔记",
|
||||||
|
"path": "000-inbox/Docker 核心知识与实战笔记.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "ubuntu",
|
||||||
|
"path": "resource/系统/ubuntu.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "tg-bot",
|
||||||
|
"path": "000-inbox/tg-bot.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260326141824",
|
||||||
|
"path": "000-Inbox/20260326141824.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260326140857",
|
||||||
|
"path": "000-Inbox/20260326140857.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260326093371",
|
||||||
|
"path": "000-Inbox/20260326093371.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "核心策略",
|
||||||
|
"path": "resource/ai/核心策略.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "002 vllm 安装日志",
|
||||||
|
"path": "resource/ai/大模型安装笔记/002 vllm 安装日志.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "netflix 界面切换为简中",
|
||||||
|
"path": "resource/系统/netflix 界面切换为简中.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "构建 HUGO 博客的完整指南:从搭建到部署",
|
||||||
|
"path": "resource/系统/构建 HUGO 博客的完整指南:从搭建到部署.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260325172730",
|
||||||
|
"path": "000-Inbox/20260325172730.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "服务器-香港",
|
||||||
|
"path": "personal/服务器-香港.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260325150017",
|
||||||
|
"path": "000-Inbox/20260325150017.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "Prompt 03 COSMIC 子过程",
|
||||||
|
"path": "resource/ai/prompts/cosmic/Prompt 03 COSMIC 子过程.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "003 vllm 启动日志",
|
||||||
|
"path": "resource/ai/大模型安装笔记/003 vllm 启动日志.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260325083535",
|
||||||
|
"path": "000-Inbox/20260325083535.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "20260324182248",
|
||||||
|
"path": "000-Inbox/20260324182248.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "接口收纳",
|
||||||
|
"path": "work/移动杭研/业务梳理/接口收纳.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "开发笔记",
|
||||||
|
"path": "work/移动杭研/开发记录/7.18.0/开发笔记.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "0323-邮件发送异常",
|
||||||
|
"path": "work/移动杭研/问题处理/2026-03/0323-邮件发送异常.md"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"basename": "TG 备忘录",
|
||||||
|
"path": "personal/TG 备忘录.md"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"basename": "CLAUDE.md",
|
"basename": "CLAUDE.md",
|
||||||
"path": "work/移动杭研/AI 项目/CLAUDE.md.md"
|
"path": "work/移动杭研/AI 项目/CLAUDE.md.md"
|
||||||
@@ -75,86 +199,6 @@
|
|||||||
{
|
{
|
||||||
"basename": "Prompt 06 COSMIC 锐评",
|
"basename": "Prompt 06 COSMIC 锐评",
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 06 COSMIC 锐评.md"
|
"path": "resource/ai/prompts/cosmic/Prompt 06 COSMIC 锐评.md"
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Prompt 05 COSMIC 时序图",
|
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 05 COSMIC 时序图.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Prompt 04 COSMIC PRD 文档",
|
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 04 COSMIC PRD 文档.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Prompt 03 COSMIC 子过程",
|
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 03 COSMIC 子过程.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Prompt 02 COSMIC 功能过程",
|
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 02 COSMIC 功能过程.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Prompt 00 COSMIC v1",
|
|
||||||
"path": "resource/ai/prompts/cosmic/Prompt 00 COSMIC v1.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260319165480",
|
|
||||||
"path": "000-Inbox/20260319165480.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "RAG Flow 部署",
|
|
||||||
"path": "work/移动杭研/AI 项目/RAG Flow 部署.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "杭州服务器-172.21.30.23-AI",
|
|
||||||
"path": "work/移动杭研/项目备忘/杭州服务器-172.21.30.23-AI.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "settings.local.json",
|
|
||||||
"path": "work/移动杭研/AI 项目/settings.local.json.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "RAG Flow",
|
|
||||||
"path": "work/移动杭研/AI 项目/RAG Flow.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260318101127",
|
|
||||||
"path": "000-Inbox/20260318101127.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260318100374",
|
|
||||||
"path": "000-Inbox/20260318100374.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "ubuntu",
|
|
||||||
"path": "resource/系统/ubuntu.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "Anolis 系统 Redis 安装",
|
|
||||||
"path": "resource/组件/Anolis 系统 Redis 安装.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "常用命令",
|
|
||||||
"path": "resource/常用命令.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260316213546",
|
|
||||||
"path": "000-Inbox/20260316213546.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260316160264",
|
|
||||||
"path": "000-Inbox/20260316160264.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260316102936",
|
|
||||||
"path": "000-Inbox/20260316102936.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "20260316105203",
|
|
||||||
"path": "000-Inbox/20260316105203.md"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"basename": "0316-配管任务限流问题",
|
|
||||||
"path": "work/移动杭研/问题处理/2026-03/0316-配管任务限流问题.md"
|
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"omittedPaths": [
|
"omittedPaths": [
|
||||||
|
|||||||
@@ -4,17 +4,22 @@
|
|||||||
"type": "split",
|
"type": "split",
|
||||||
"children": [
|
"children": [
|
||||||
{
|
{
|
||||||
"id": "efd0ccfc8a82680d",
|
"id": "0e5febf7350f0399",
|
||||||
"type": "tabs",
|
"type": "tabs",
|
||||||
"children": [
|
"children": [
|
||||||
{
|
{
|
||||||
"id": "f15a0d12f6a0fcdf",
|
"id": "bf3ca11320d7a83e",
|
||||||
"type": "leaf",
|
"type": "leaf",
|
||||||
"state": {
|
"state": {
|
||||||
"type": "empty",
|
"type": "markdown",
|
||||||
"state": {},
|
"state": {
|
||||||
|
"file": "000-inbox/x-csrf-token.md",
|
||||||
|
"mode": "source",
|
||||||
|
"source": false,
|
||||||
|
"backlinks": false
|
||||||
|
},
|
||||||
"icon": "lucide-file",
|
"icon": "lucide-file",
|
||||||
"title": "新标签页"
|
"title": "x-csrf-token"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
@@ -29,6 +34,7 @@
|
|||||||
{
|
{
|
||||||
"id": "6836caf2765d7139",
|
"id": "6836caf2765d7139",
|
||||||
"type": "tabs",
|
"type": "tabs",
|
||||||
|
"dimension": 71.87039764359352,
|
||||||
"children": [
|
"children": [
|
||||||
{
|
{
|
||||||
"id": "c8718c0c63702202",
|
"id": "c8718c0c63702202",
|
||||||
@@ -49,7 +55,7 @@
|
|||||||
"state": {
|
"state": {
|
||||||
"type": "search",
|
"type": "search",
|
||||||
"state": {
|
"state": {
|
||||||
"query": "20260324082116",
|
"query": "openclaw",
|
||||||
"matchingCase": false,
|
"matchingCase": false,
|
||||||
"explainSearch": true,
|
"explainSearch": true,
|
||||||
"collapseAll": false,
|
"collapseAll": false,
|
||||||
@@ -75,6 +81,7 @@
|
|||||||
{
|
{
|
||||||
"id": "467278b27553fb8c",
|
"id": "467278b27553fb8c",
|
||||||
"type": "tabs",
|
"type": "tabs",
|
||||||
|
"dimension": 28.12960235640648,
|
||||||
"children": [
|
"children": [
|
||||||
{
|
{
|
||||||
"id": "c7138b775f1dd80e",
|
"id": "c7138b775f1dd80e",
|
||||||
@@ -90,7 +97,7 @@
|
|||||||
}
|
}
|
||||||
],
|
],
|
||||||
"direction": "horizontal",
|
"direction": "horizontal",
|
||||||
"width": 288.5
|
"width": 302.5
|
||||||
},
|
},
|
||||||
"right": {
|
"right": {
|
||||||
"id": "ca733f6d5936ae40",
|
"id": "ca733f6d5936ae40",
|
||||||
@@ -107,12 +114,13 @@
|
|||||||
"state": {
|
"state": {
|
||||||
"type": "outline",
|
"type": "outline",
|
||||||
"state": {
|
"state": {
|
||||||
|
"file": "000-inbox/x-csrf-token.md",
|
||||||
"followCursor": true,
|
"followCursor": true,
|
||||||
"showSearch": false,
|
"showSearch": false,
|
||||||
"searchQuery": ""
|
"searchQuery": ""
|
||||||
},
|
},
|
||||||
"icon": "lucide-list",
|
"icon": "lucide-list",
|
||||||
"title": "大纲"
|
"title": "x-csrf-token 的大纲"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -139,11 +147,12 @@
|
|||||||
"state": {
|
"state": {
|
||||||
"type": "outgoing-link",
|
"type": "outgoing-link",
|
||||||
"state": {
|
"state": {
|
||||||
|
"file": "calendar/diary/2026-03-25.md",
|
||||||
"linksCollapsed": false,
|
"linksCollapsed": false,
|
||||||
"unlinkedCollapsed": true
|
"unlinkedCollapsed": true
|
||||||
},
|
},
|
||||||
"icon": "links-going-out",
|
"icon": "links-going-out",
|
||||||
"title": "出链"
|
"title": "2026-03-25 的出链列表"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -187,8 +196,7 @@
|
|||||||
"title": "脚注"
|
"title": "脚注"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
],
|
]
|
||||||
"currentTab": 2
|
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"id": "ea8a40d57ef90e62",
|
"id": "ea8a40d57ef90e62",
|
||||||
@@ -209,7 +217,7 @@
|
|||||||
}
|
}
|
||||||
],
|
],
|
||||||
"direction": "horizontal",
|
"direction": "horizontal",
|
||||||
"width": 286.5
|
"width": 300.5
|
||||||
},
|
},
|
||||||
"left-ribbon": {
|
"left-ribbon": {
|
||||||
"hiddenItems": {
|
"hiddenItems": {
|
||||||
@@ -223,54 +231,54 @@
|
|||||||
"obsidian-excalidraw-plugin:New drawing": false
|
"obsidian-excalidraw-plugin:New drawing": false
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"active": "f15a0d12f6a0fcdf",
|
"active": "bf3ca11320d7a83e",
|
||||||
"lastOpenFiles": [
|
"lastOpenFiles": [
|
||||||
"000-inbox/20260324090682.md",
|
"calendar/diary/2026-03-27.md",
|
||||||
"000-Inbox/20260324090682.md",
|
"000-inbox/需求-命中率计算.md",
|
||||||
"000-inbox/20260324085410.md",
|
"resource/前端/如何成为一个 React 工程师呢?.md",
|
||||||
"000-inbox/20260324085482.md",
|
"000-inbox/20260327101490.md",
|
||||||
"000-inbox/20260324085466.md",
|
"000-Inbox/20260327113359.md",
|
||||||
"000-Inbox/20260324085482.md",
|
"000-Inbox/20260327151942.md",
|
||||||
"000-Inbox/20260324085410.md",
|
"000-inbox/20260327151942.md",
|
||||||
"000-Inbox/20260324085466.md",
|
"000-inbox/x-csrf-token.md",
|
||||||
"attachment/templates/日常记录-日记模板.md",
|
"000-Inbox/20260327105648.md",
|
||||||
"attachment/templates/日常记录-闪念笔记.md",
|
"calendar/diary/2026-03-02.md",
|
||||||
"000-inbox/20260324084778.md",
|
"000-Inbox/20260327101490.md",
|
||||||
"000-Inbox/20260324084778.md",
|
"calendar/diary/2026-03-23.md",
|
||||||
"work/移动杭研/开发记录/7.18.0/开发笔记.md",
|
"calendar/diary/2026-03-20.md",
|
||||||
|
"calendar/diary/2026-03-21.md",
|
||||||
|
"calendar/diary/2026-03-26.md",
|
||||||
|
"calendar/diary/2026-03-25.md",
|
||||||
"calendar/diary/2026-03-24.md",
|
"calendar/diary/2026-03-24.md",
|
||||||
"000-inbox/tg-bot.md",
|
"calendar/diary/2026-03-19.md",
|
||||||
"000-inbox/Docker 核心知识与实战笔记.md",
|
"calendar/diary/2026-03-18.md",
|
||||||
"attachment/Pasted image 20260324082116.png",
|
"calendar/diary/2026-03-17.md",
|
||||||
"000-inbox/0323-1.md",
|
"calendar/diary/2026-03-16.md",
|
||||||
"000-Inbox/20260324082507.md",
|
"calendar/diary/2026-03-13.md",
|
||||||
"000-inbox/20260324082570.md",
|
"calendar/diary/2026-03-12.md",
|
||||||
"000-inbox/202603232149292.md",
|
"calendar/diary/2026-03-11.md",
|
||||||
"000-inbox/20260324082507.md",
|
"calendar/diary/2026-03-10.md",
|
||||||
"000-inbox/20260324081861.md",
|
"calendar/diary/2026-03-09.md",
|
||||||
"000-inbox/20260323215788.md",
|
"attachment/image-20260325224201537.png",
|
||||||
"000-inbox/20260323215783.md",
|
"attachment/image-20260325224152205.png",
|
||||||
"000-Inbox/20260324082570.md",
|
"attachment/image-20260325224141721.png",
|
||||||
"attachment/templates/时间戳笔记 1.md",
|
"attachment/image-20260325224132102.png",
|
||||||
"attachment/image-20260324081512980.png",
|
"attachment/image-20260325224123001.png",
|
||||||
"attachment/Pasted image 20260323220004.png",
|
"attachment/image-20260325224113880.png",
|
||||||
"attachment/Pasted image 20260323214940.png",
|
"attachment/image-20260325224055087.png",
|
||||||
"attachment/image-20260323215003621.png",
|
"attachment/image-20260325224046176.png",
|
||||||
"attachment/images-uuid/3284aebc70ac4b04bed34178af47de22.png",
|
"attachment/image-20260325224034041.png",
|
||||||
"attachment/images-uuid/44afb467c5294b4ea0a437b3b3258f5c.png",
|
"attachment/image-20260325224025519.png",
|
||||||
"attachment/images-paste/image-20260323102328859.png",
|
"resource/ai/大模型安装笔记",
|
||||||
"work/移动杭研/问题处理/2026-03",
|
"work/移动杭研/问题处理/2026-03",
|
||||||
"resource/ai/prompts/cosmic 业务版本",
|
"resource/ai/prompts/cosmic 业务版本",
|
||||||
"resource/ai/prompts/cosmic",
|
"resource/ai/prompts/cosmic",
|
||||||
"resource/ai/prompts/临时",
|
"resource/ai/prompts/临时",
|
||||||
"resource/工具/rime",
|
"resource/工具/rime",
|
||||||
"attachment/images-paste/image-20260304153545122.png",
|
|
||||||
"work/移动杭研/开发记录/7.19.0",
|
"work/移动杭研/开发记录/7.19.0",
|
||||||
"work/移动杭研/AI 项目",
|
"work/移动杭研/AI 项目",
|
||||||
"resource/前端",
|
"resource/前端",
|
||||||
"resource/英语",
|
"resource/英语",
|
||||||
"attachment/images-paste/image-20260305082403915.png",
|
"000-inbox/未命名.canvas"
|
||||||
"000-inbox/未命名.canvas",
|
|
||||||
"resource/mermaid"
|
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
@@ -0,0 +1,40 @@
|
|||||||
|
# 常用 Screen 命令大全
|
||||||
|
|
||||||
|
## 创建会话(最常用)
|
||||||
|
|
||||||
|
- `screen -U -S vllm_server` → 新建并命名
|
||||||
|
- `screen -U -dmS vllm_server` → **新建后立即分离**(最推荐!直接后台启动)
|
||||||
|
- `screen -U -dmS vllm_server "python -m vllm serve …"` → 新建 + 直接执行命令(一键启动服务)
|
||||||
|
|
||||||
|
## 管理会话
|
||||||
|
|
||||||
|
- `screen -U -ls` 或 `screen -U -list` → 列出所有会话(你现在用的)
|
||||||
|
- `screen -U -r` → 进入最后一个会话
|
||||||
|
- `screen -U -r vllm_server` → 按名字进入(推荐,比数字更稳)
|
||||||
|
- `screen -U -r 89505` → 只输入数字也可以(简写)
|
||||||
|
- `screen -U -S vllm_server -X quit` → 杀死指定会话(你现在用的)
|
||||||
|
- `screen -wipe` → 清理已死亡的会话记录(偶尔用)
|
||||||
|
|
||||||
|
# 在 screen 里面的快捷键(记住这几个就够用 90%)
|
||||||
|
|
||||||
|
| 快捷键 | 功能 |
|
||||||
|
|--------|------|
|
||||||
|
| `Ctrl-a ?` | 显示帮助(所有快捷键列表) |
|
||||||
|
| `Ctrl-a c` | 新建一个窗口(像 tab) |
|
||||||
|
| `Ctrl-a n` / `Ctrl-a p` | 切换到下一个/上一个窗口 |
|
||||||
|
| `Ctrl-a 0~9` | 直接跳到第几个窗口 |
|
||||||
|
| `Ctrl-a d` | 分离(退出) |
|
||||||
|
| `Ctrl-a k` | 杀死当前窗口(确认 y) |
|
||||||
|
| `Ctrl-a A` | 重命名当前窗口(好认) |
|
||||||
|
| `Ctrl-a "` | 显示窗口列表,选择切换 |
|
||||||
|
|
||||||
|
# 高级实用技巧
|
||||||
|
|
||||||
|
- 滚动屏幕:`Ctrl-a [` → 进入复制模式,用上下键翻历史,按 `Esc` 退出
|
||||||
|
- 发送命令给后台会话:`screen -S vllm_server -X stuff "echo hello\n"`
|
||||||
|
- 自动启动 vLLM(推荐写进脚本):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
screen -U -dmS vllm_server
|
||||||
|
screen -S vllm_server -X stuff "python -m vllm serve --model /root/autodl-tmp/DeepSeek-R1-1.5B --port 8000\n"
|
||||||
|
```
|
||||||
@@ -0,0 +1,3 @@
|
|||||||
|
```
|
||||||
|
{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = message['content'].replace('</think>', '').split('<think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}
|
||||||
|
```
|
||||||
@@ -0,0 +1,53 @@
|
|||||||
|
`x-csrf-token` 是 Spring Security CSRF 防护机制 的一部分,用于防止跨站请求伪造(CSRF)攻击。
|
||||||
|
|
||||||
|
后端接口需要通过请求头接收前端携带的 CSRF token,以验证请求的合法性。
|
||||||
|
|
||||||
|
其中 IBSCsrfTokenRepository 管理 CSRF token,是一个 `UUID.randomUUID().toString()` 随机字符串
|
||||||
|
|
||||||
|
登录成功后,SecurityConfig.writeLoginSuccessResult()(SecurityConfig.java:482)会将 token 存入 session:request.getSession().setAttribute(IBSCsrfTokenRepository.class.getName() + ".CSRF_TOKEN", token)
|
||||||
|
|
||||||
|
同时通过 /admin/getCurrentUser 接口返回给前端:userVO.setCsrfToken(csrfToken.getToken())
|
||||||
|
|
||||||
|
```
|
||||||
|
前端获取 Token
|
||||||
|
前端有两套机制,取决于环境:
|
||||||
|
|
||||||
|
生产环境(cdn-web 模板):页面通过 Thymeleaf 模板将 token 渲染到 HTML meta 标签中
|
||||||
|
|
||||||
|
|
||||||
|
<meta name="_csrf" th:content="${_csrf.token}">
|
||||||
|
<meta name="_csrf_header" th:content="${_csrf.headerName}">
|
||||||
|
前端通过 getCsrfHeaderFromMeta() 读取这两个 meta 标签,动态设置请求头。
|
||||||
|
|
||||||
|
非生产环境(IBS-web):通过调用 /admin/getCurrentUser 接口获取 token 并缓存在 window.XTOKEN 中。
|
||||||
|
```
|
||||||
|
|
||||||
|
后端 Filter 链验证 Token
|
||||||
|
|
||||||
|
RequestReplaceFilter
|
||||||
|
|
||||||
|
```
|
||||||
|
response.setHeader("Access-Control-Allow-Headers",
|
||||||
|
"content-type,x-requested-with,Authorization, x-request-with,x-ui-request,lang,x-csrf-token,csrf-token");
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
在 SecurityConfig.csrf() 配置中(SecurityConfig.java:211-218),以下路径不进行 CSRF 校验:
|
||||||
|
|
||||||
|
// CSRF
|
||||||
|
String[] ignorePathes = {"/v1/**", "/v2/**", "/v1.0/**", "/analyzer/**", "/puppet/**", "/api/**",
|
||||||
|
"/sso/**", "/ssoapi/**", "/dss/prohibit/**", "/dss/v1/log/subscribe/callback", "/portal/**",
|
||||||
|
"/param/config/**", "/bboss/**", "/sync/BBOSS/**", "/download/exportFile", "/action", "/actionpm",
|
||||||
|
"/action/cms", "/action/cdn/statistics", "/action/enterprise/domains","/action/enterprise/productId/domains",
|
||||||
|
"/action/js", "/content/delivery/**", "/information/**","/testAction","/api/v2/**",
|
||||||
|
"/home/page/help/Doc/**", "/home/page/security/**", "/query/cmcc/party/**", "/query/enterprise/domain/info", "/v2.0/log/template/**"};
|
||||||
|
http.csrf().ignoringAntMatchers(ignorePathes)
|
||||||
|
.csrfTokenRepository(new IBSCsrfTokenRepository(Arrays.asList(ignorePathes)));//不塞在cookie中
|
||||||
|
```
|
||||||
|
|
||||||
|
如果请求路径在 ignorePathes 列表中(如 /v1/**, /api/**, /action, /actionpm 等),loadToken 返回硬编码的 "1111111111",此时:
|
||||||
|
|
||||||
|
请求带 X-CSRF-TOKEN: 1111111111 → 可以通过
|
||||||
|
|
||||||
|
请求带 X-CSRF-TOKEN: 任意UUID → 失败
|
||||||
@@ -0,0 +1,139 @@
|
|||||||
|
```
|
||||||
|
{
|
||||||
|
"model": "deepseek-chat",
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "北京现在的天气怎么样?"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"tools": [
|
||||||
|
{
|
||||||
|
"type": "function",
|
||||||
|
"function": {
|
||||||
|
"name": "get_weather",
|
||||||
|
"description": "获取指定城市的天气信息",
|
||||||
|
"parameters": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"city": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "城市名称"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": [
|
||||||
|
"city"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"tool_choice": "auto"
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
{
|
||||||
|
"id": "06bcc2b7-602a-474b-bdd3-01cea249b121",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774519072,
|
||||||
|
"model": "deepseek-chat",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "我来帮您查询北京的天气情况。",
|
||||||
|
"tool_calls": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"id": "call_00_s4Qs5fJiG0yeRTpOgYxnxRyp",
|
||||||
|
"type": "function",
|
||||||
|
"function": {
|
||||||
|
"name": "get_weather",
|
||||||
|
"arguments": "{\"city\": \"北京\"}"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"logprobs": null,
|
||||||
|
"finish_reason": "tool_calls"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 309,
|
||||||
|
"completion_tokens": 51,
|
||||||
|
"total_tokens": 360,
|
||||||
|
"prompt_tokens_details": {
|
||||||
|
"cached_tokens": 0
|
||||||
|
},
|
||||||
|
"prompt_cache_hit_tokens": 0,
|
||||||
|
"prompt_cache_miss_tokens": 309
|
||||||
|
},
|
||||||
|
"system_fingerprint": "fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"model": "deepseek-chat",
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "给我返回一个水果的信息,包含名称和颜色"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"response_format": {
|
||||||
|
"type": "json_schema",
|
||||||
|
"json_schema": {
|
||||||
|
"name": "fruit",
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"name": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "水果名称"
|
||||||
|
},
|
||||||
|
"color": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "水果颜色"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": [
|
||||||
|
"name",
|
||||||
|
"color"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"id": "chatcmpl-2b2225c5-02d0-4817-8039-329b3c790128",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774519551,
|
||||||
|
"model": "gpt-5.4",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "{\"color\":\"红色\",\"name\":\"苹果\"}"
|
||||||
|
},
|
||||||
|
"finish_reason": "stop"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 80,
|
||||||
|
"completion_tokens": 17,
|
||||||
|
"total_tokens": 97,
|
||||||
|
"prompt_tokens_details": {},
|
||||||
|
"completion_tokens_details": {
|
||||||
|
"reasoning_tokens": 0,
|
||||||
|
"accepted_prediction_tokens": 0,
|
||||||
|
"rejected_prediction_tokens": 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
@@ -0,0 +1,24 @@
|
|||||||
|
|
||||||
|
```
|
||||||
|
http://dev.p.cdn.10086.cn:8080
|
||||||
|
|
||||||
|
/statistics/getHitRatio
|
||||||
|
|
||||||
|
?cpId=*
|
||||||
|
&product=*
|
||||||
|
&affectAreas=
|
||||||
|
&domainNames=
|
||||||
|
&provider=*
|
||||||
|
&startTime=2026-03-27%2010:25
|
||||||
|
&endTime=2026-03-27%2010:25
|
||||||
|
&productId=
|
||||||
|
&isps=
|
||||||
|
&granular=0
|
||||||
|
&_=1774580169469
|
||||||
|
```
|
||||||
|
|
||||||
|
com.cmcc.cdn.platform.selfservice.controller.StatisticsController#getHitRatio
|
||||||
|
|
||||||
|
给我梳理下这个接口的功能,输出一个 markdown 文档到项目的根目录。
|
||||||
|
|
||||||
|
主要是用到哪些参数,有哪些校验,有没有参数转换和默认值。掉了哪些三方接口,调了接口后做了哪些事情。尽量清晰。注意细节。
|
||||||
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
{kind=link}
|
After Width: | Height: | Size: 156 KiB |
{kind=link}
|
After Width: | Height: | Size: 91 KiB |
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
{kind=link}
|
After Width: | Height: | Size: 97 KiB |
{kind=link}
|
After Width: | Height: | Size: 54 KiB |
{kind=link}
|
After Width: | Height: | Size: 88 KiB |
{kind=link}
|
After Width: | Height: | Size: 146 KiB |
{kind=link}
|
After Width: | Height: | Size: 81 KiB |
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
{kind=link}
|
After Width: | Height: | Size: 95 KiB |
{kind=link}
|
After Width: | Height: | Size: 89 KiB |
{kind=link}
|
After Width: | Height: | Size: 74 KiB |
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
@@ -11,7 +11,9 @@
|
|||||||
寅杰说需要配管反向提交资料,确认下提交什么。
|
寅杰说需要配管反向提交资料,确认下提交什么。
|
||||||
|
|
||||||
3.8 系统提示优化 - 信安错误提醒优化(5 天)
|
3.8 系统提示优化 - 信安错误提醒优化(5 天)
|
||||||
|
|
||||||
4.1 政企侧用户体验优化(2 天)
|
4.1 政企侧用户体验优化(2 天)
|
||||||
|
|
||||||
5.5 试商用客户峰值带宽增加引入省份信息(2 天)
|
5.5 试商用客户峰值带宽增加引入省份信息(2 天)
|
||||||
|
|
||||||
# 总结
|
# 总结
|
||||||
|
|||||||
@@ -24,10 +24,6 @@ excalicode-ai 是我之前的一个大项目,其中包含各种模块和功能
|
|||||||
|
|
||||||
11:融合 1 平面
|
11:融合 1 平面
|
||||||
|
|
||||||
cli_a9381b92c0b8dbd8
|
|
||||||
|
|
||||||
KySVktr83JyJGaQR9GnJDesxLx5z3Gw2
|
|
||||||
|
|
||||||
OpenClaw: access not configured.
|
OpenClaw: access not configured.
|
||||||
|
|
||||||
Your Feishu user id: ou_5c0794859a5a52712cbfb49aaa334b70
|
Your Feishu user id: ou_5c0794859a5a52712cbfb49aaa334b70
|
||||||
|
|||||||
@@ -71,3 +71,5 @@ ps -ef | grep xinan
|
|||||||
```
|
```
|
||||||
|
|
||||||
# 总结
|
# 总结
|
||||||
|
|
||||||
|
日报有问题。了解了一些概念。
|
||||||
|
|||||||
@@ -1,8 +1,10 @@
|
|||||||
# 任务
|
# 任务
|
||||||
|
|
||||||
- [ ] 开发:参加 IBS 项目晨会,同步昨日问题跟进事项。(李春良)
|
- [x] 开发:参加 IBS 项目晨会,同步昨日问题跟进事项。追踪信安信息邮件问题。(李春良 0.5)
|
||||||
- [ ] 开发:支撑 IBS V7.19.0 版本测试。新业务平面引入与系统集成实施。(李春良)
|
- [x] 开发:支撑 IBS V7.19.0 版本测试。新业务平面引入与系统集成实施。合作服务商 显示问题。(李英浩 1)
|
||||||
|
|
||||||
# 日志
|
# 日志
|
||||||
|
|
||||||
# 总结
|
# 总结
|
||||||
|
|
||||||
|
张雪峰去世了。
|
||||||
|
|||||||
@@ -0,0 +1,33 @@
|
|||||||
|
# 任务
|
||||||
|
|
||||||
|
- [x] 开发:参加 IBS 项目晨会,同步昨日问题跟进事项。(李春良 0.5)
|
||||||
|
- [x] 开发:支撑 IBS V7.19.0 版本测试。新业务平面引入与系统集成实施。接口确认(郑子雯 1)
|
||||||
|
- [x] 项目:IBS 智能体调研,简化 MCP 接口逻辑。(张鹏豪 6.5)
|
||||||
|
|
||||||
|
# 日志
|
||||||
|
|
||||||
|
杭州是满血大概只有 8K。
|
||||||
|
|
||||||
|
咋们的蒸馏大概只有 4K。
|
||||||
|
|
||||||
|
1. vllm 可以控制请求时间么?
|
||||||
|
2. 是否开启思考是否可以控制?
|
||||||
|
3. vllm 启动有哪些可以控制。
|
||||||
|
|
||||||
|
deepseek-reasoner
|
||||||
|
|
||||||
|
DeepSeek-V3.2
|
||||||
|
(思考模式)
|
||||||
|
|
||||||
|
可以控制是否思考?
|
||||||
|
|
||||||
|
| 参数 | 不传默认值 | 传什么 | 作用 | 影响什么 |
|
||||||
|
| --------------------------- | ----------- | ----------------------------------------------------------------------- | ----------------- | -------------------------------------------------- |
|
||||||
|
| `--enable-auto-tool-choice` | 默认关闭(False) | 传 `--enable-auto-tool-choice` 开启;或显式传 `--no-enable-auto-tool-choice` 关闭 | 允许模型自己决定是否调用工具 | 不开时,模型通常不会主动发起 tool call;开了后,模型可根据问题自动选择 MCP/tool |
|
||||||
|
| `--tool-call-parser` | 默认无(None) | 传一个解析器名字,比如 `openai`、`llama3_json`、`hermes`、`mistral`、`qwen3_xml` 等 | 指定如何解析模型输出的工具调用格式 | 不传时,即使模型输出了工具调用内容,也可能无法被正确识别;传错了会导致 tool call 解析失败 |
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
# 总结
|
||||||
|
|
||||||
|
这两天在自己部署模型。想了解一些模型的概念。
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
# 任务
|
||||||
|
|
||||||
|
- [x] 开发:参加 IBS 项目晨会,同步昨日问题跟进事项。(李春良 0.5)
|
||||||
|
- [x] 开发:支撑 IBS V7.19.0 版本测试。新业务平面引入与系统集成实施。确认 2.7查询某域名具体配置信息(基础+高级配置)为什么无法触发平面。(郑子雯 1)
|
||||||
|
- [x] 客响:直播控制台无法导出。(后台时间过长)(李春良 0.5)
|
||||||
|
- [x] 前端:企业白名单、cache+二级域名白名单问题。(白寰宇 0.5)
|
||||||
|
- [x] 项目:IBS 智能体调研讨论,模型功能方向。(田卓 5.5)
|
||||||
|
|
||||||
|
# 日志
|
||||||
|
|
||||||
|
CoT 思考链
|
||||||
|
|
||||||
|
1. 到底是不是想要的。
|
||||||
|
2. 组件选型。
|
||||||
|
|
||||||
|
# 总结
|
||||||
|
|
||||||
|
这两天仔细了解了一下模型的安装部署,性能,以及工具调用协议等等。
|
||||||
|
|
||||||
|
首先感觉脑子里清晰了很多。
|
||||||
|
|
||||||
|
我发现我现在一个毛病,我想过多的了解更多的内容,导致我其实有个很大的问题,我总会挖的过深。然后脑子里积压过多的东西。然后当我瞬间轻松下来脑子里又一股脑的都出来了。笔记工具是我一个巨大的助力和习惯,让我有的追溯。
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
# 任务
|
||||||
|
|
||||||
|
- [x] 开发:参加 IBS 项目晨会,同步昨日问题跟进事项。(李春良 0.5)
|
||||||
|
- [x] 项目:内容网络IBS系统研发项目_IBS子项目3月任务清单。(李春良 1)
|
||||||
|
- [ ] 开发:请求命中率计算问题。
|
||||||
|
|
||||||
|
# 日志
|
||||||
|
|
||||||
|
同步两个我个人的想法你们可以看看
|
||||||
|
|
||||||
|
DeepSeek-R1-Distill-Qwen-32B 接口似乎不支持 Tool Calling 和 Function Calling,虽然能靠底座 Qwen 的能力绕过,但接口标准是否一致还需本地验证。现在测试一直是用的官方的 API,别到最后咋们这边不适配就很难受。
|
||||||
|
|
||||||
|
128G 卡跑 32B,如果追求效果用 16bit 加大上下文比如顶满 128K ,剩下的显存留给 KV Cache 根本撑不住几个并发;如果为了高并发切到 8bit 量化加 8K 上下文,工具调用能力大概率会直线下降。所以这个资源和模型最好能快些定下来,用自己的资源测试,就会有一些实际的体感。
|
||||||
|
|
||||||
|
模型牛,人就轻松;模型弱,调试提示词和工具就要好久好久时间。
|
||||||
|
|
||||||
|
总是用官方满血测试就有一种啥啥都好的错觉。
|
||||||
|
|
||||||
|
实际效果我不知道,但我感觉涉及工具调用决策等等应该更看模型能力了。
|
||||||
|
|
||||||
|
评估具体实现方案,分为四大模块处理:
|
||||||
|
|
||||||
|
1. 运营数据
|
||||||
|
2. 话单
|
||||||
|
3. CDN集中运管平台接口规范扩展
|
||||||
|
4. BPM对接接口规范扩展
|
||||||
|
|
||||||
|
完成数据统计、实时监控、内容中心、用量查询、统计报表、运营指标导出、业务运维/配置管理、全站加速控制台/统计分析/数据统计、直播控制台/域名管理、冲突域名管理等页面开发。
|
||||||
|
|
||||||
|
完成计费对账、自有业务中间话单统计等页面开发。
|
||||||
|
|
||||||
|
完成以下接口适配创建/修改加速域名信息、域名配置回调接口(接口方向:CDN集中运维平台->IBS平台)、启用/停用加速域名、查询平面分发的所有加速域名列表、查询加速域名列表(基础配置)、查询某域名具体配置信息(基础+高级配置)、增加/修改域名高级配置、内容预热、内容刷新、内容分发、Url封禁/解禁。
|
||||||
|
|
||||||
|
完成以下接口适配IBS通用运维任务创建接口(IBS->BPM)、通用任务状态回传接口(BPM->IBS)、业务适配工单验收反馈接口(BPM->IBS)、业务适配工单阶段反馈接口(BPM->IBS)、域名平面同步接口(BPM->IBS)
|
||||||
|
|
||||||
|
完成运营数据需求开发自测,具备联调条件
|
||||||
|
|
||||||
|
完成话单需求开发自测,具备联调条件
|
||||||
|
|
||||||
|
完成CDN集中运管平台接口规范扩展需求开发自测,具备联调条件
|
||||||
|
|
||||||
|
完成BPM对接接口规范扩展需求开发自测,具备联调条件
|
||||||
|
|
||||||
|
# 总结
|
||||||
@@ -0,0 +1,43 @@
|
|||||||
|
硬件:NVIDIA A800 80GB GPU,30GB 系统盘 和 100GB 数据盘 (`/root/autodl-tmp`)。
|
||||||
|
|
||||||
|
> **19.5 TFLOPS** = 普通生产线能力
|
||||||
|
> **312 Tensor TFLOPS** = AI 专用流水线能力
|
||||||
|
|
||||||
|
模型:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
|
||||||
|
|
||||||
|
> Tensor type BF16
|
||||||
|
> Tensor type(张量类型)通常指 PyTorch 或 TensorFlow 等框架中,用于表示多维数组的数据对象。通俗理解模型内部数字是用什么“数据格式”来存的。
|
||||||
|
> 33B × 2 字节 ≈ 66GB
|
||||||
|
|
||||||
|
服务器启动日志
|
||||||
|
|
||||||
|
```
|
||||||
|
+-----------------------------------------------AutoDL-----------------------------------------------------+
|
||||||
|
目录说明:
|
||||||
|
╔═════════════════╦════════╦════╦═════════════════════════════════════════════════════════════════════════╗
|
||||||
|
║目录 ║名称 ║速度║说明 ║
|
||||||
|
╠═════════════════╬════════╬════╬═════════════════════════════════════════════════════════════════════════╣
|
||||||
|
║/ ║系 统 盘║一般║实例关机数据不会丢失,可存放代码等。会随保存镜像一起保存。 ║
|
||||||
|
║/root/autodl-tmp ║数 据 盘║ 快 ║实例关机数据不会丢失,可存放读写IO要求高的数据。但不会随保存镜像一起保存 ║
|
||||||
|
╚═════════════════╩════════╩════╩═════════════════════════════════════════════════════════════════════════╝
|
||||||
|
CPU :14 核心
|
||||||
|
内存:120 GB
|
||||||
|
GPU :NVIDIA A800 80GB PCIe, 1
|
||||||
|
存储:
|
||||||
|
系 统 盘/ :1% 53M/30G
|
||||||
|
数 据 盘/root/autodl-tmp:1% 12K/100G
|
||||||
|
+----------------------------------------------------------------------------------------------------------+
|
||||||
|
*注意:
|
||||||
|
1.系统盘较小请将大的数据存放于数据盘或文件存储中,重置系统时数据盘和文件存储中的数据不受影响
|
||||||
|
2.清理系统盘请参考:https://www.autodl.com/docs/qa1/
|
||||||
|
3.终端中长期执行命令请使用screen等工具开后台运行,确保程序不受SSH连接中断影响:https://www.autodl.com/docs/daemon/
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
显卡检测
|
||||||
|
|
||||||
|
```
|
||||||
|
root@autodl-container-c6d54aa471-4479d4d0:~# python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
|
||||||
|
True
|
||||||
|
NVIDIA A800 80GB PCIe
|
||||||
|
```
|
||||||
@@ -0,0 +1,172 @@
|
|||||||
|
# 第一步:准备环境与配置下载源
|
||||||
|
|
||||||
|
`DeepSeek-R1-Distill-Qwen-32B` 的模型权重(BF16/FP16精度)大约需要占用 **64GB 的磁盘空间** 和 **约 65GB 的显存**。
|
||||||
|
|
||||||
|
**A800 80GB 显存完美支持该模型单卡运行**,但**系统盘(30GB)空间不足**,因此将模型下载到数据盘(`/root/autodl-tmp`)中。
|
||||||
|
|
||||||
|
通过国内镜像站下载,并**强制将缓存路径设置在数据盘**,防止系统盘撑爆导致实例死机。
|
||||||
|
|
||||||
|
在终端中依次执行以下命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 1. 进入数据盘目录
|
||||||
|
cd /root/autodl-tmp
|
||||||
|
|
||||||
|
# 2. 必须:设置 Hugging Face 缓存目录到数据盘
|
||||||
|
export HF_HOME=/root/autodl-tmp/hf_cache
|
||||||
|
|
||||||
|
# 3. 设置 Hugging Face 国内镜像加速下载
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
|
||||||
|
# 4. 安装 huggingface-cli 及加速传输依赖
|
||||||
|
pip install -U huggingface_hub hf_transfer
|
||||||
|
|
||||||
|
如果遇到风险
|
||||||
|
pip install -U huggingface_hub hf_transfer --break-system-packages
|
||||||
|
|
||||||
|
export HF_HUB_ENABLE_HF_TRANSFER=1
|
||||||
|
```
|
||||||
|
|
||||||
|
# 第二步:下载模型
|
||||||
|
|
||||||
|
**方式一**
|
||||||
|
|
||||||
|
使用 `huggingface-cli` 将模型直接下载到数据盘的指定文件夹中。下载大概需要十几到几十分钟(约 64 GB)。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --local-dir /root/autodl-tmp/DeepSeek-R1-32B
|
||||||
|
|
||||||
|
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir /root/autodl-tmp/DeepSeek-R1-1.5B
|
||||||
|
|
||||||
|
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-7B
|
||||||
|
```
|
||||||
|
|
||||||
|
**方式二**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python - <<'PY'
|
||||||
|
import os
|
||||||
|
from huggingface_hub import snapshot_download
|
||||||
|
|
||||||
|
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
|
||||||
|
os.environ["HF_HOME"] = "/root/autodl-tmp/hf_cache"
|
||||||
|
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
||||||
|
|
||||||
|
print("⏳ 开始下载模型...")
|
||||||
|
path = snapshot_download(
|
||||||
|
repo_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
|
||||||
|
local_dir="/root/autodl-tmp/DeepSeek-R1-1.5B",
|
||||||
|
)
|
||||||
|
|
||||||
|
print("✅ 下载完成,模型目录:", path)
|
||||||
|
PY
|
||||||
|
```
|
||||||
|
|
||||||
|
# 第三步:安装并启动 vLLM 推理框架
|
||||||
|
|
||||||
|
**1. 安装 vLLM:**
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
**2. 开启后台运行:**
|
||||||
|
|
||||||
|
使用 `screen` 创建一个叫 `vllm_server` 的后台窗口:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
创建
|
||||||
|
screen -U -S vLLM
|
||||||
|
|
||||||
|
列表
|
||||||
|
screen -U -ls
|
||||||
|
|
||||||
|
重新进入
|
||||||
|
screen -U -r 89505.vllm_server
|
||||||
|
|
||||||
|
退出
|
||||||
|
screen -U -S 7394 -X quit
|
||||||
|
|
||||||
|
离开
|
||||||
|
Ctrl-a d
|
||||||
|
```
|
||||||
|
|
||||||
|
**3. 启动类似 OpenAI 的 API 服务:**
|
||||||
|
|
||||||
|
注意:我们将端口设为 `6006`,这是 AutoDL 官方支持对外暴露的默认端口
|
||||||
|
|
||||||
|
前台
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m vllm.entrypoints.openai.api_server \
|
||||||
|
--model /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-7B \
|
||||||
|
--served-model-name deepseek-r1 \
|
||||||
|
--tensor-parallel-size 1 \
|
||||||
|
--max-model-len 131072 \
|
||||||
|
--gpu-memory-utilization 0.95 \
|
||||||
|
--reasoning-parser deepseek_r1 \
|
||||||
|
--tool-call-parser qwen3_xml \
|
||||||
|
--enable-auto-tool-choice \
|
||||||
|
--port 6006
|
||||||
|
```
|
||||||
|
|
||||||
|
后台
|
||||||
|
|
||||||
|
```bash
|
||||||
|
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
|
||||||
|
|
||||||
|
screen -U -L -Logfile /root/vllm_server.log -dmS vllm_server bash -c 'python -m vllm.entrypoints.openai.api_server \
|
||||||
|
--model /root/autodl-tmp/DeepSeek-R1-32B \
|
||||||
|
--served-model-name deepseek-r1 \
|
||||||
|
--tensor-parallel-size 1 \
|
||||||
|
--max-model-len 8192 \
|
||||||
|
--gpu-memory-utilization 0.95 \
|
||||||
|
--port 6006'
|
||||||
|
|
||||||
|
screen -U -L -Logfile /root/vllm_server.log -dmS vllm_server bash -c 'python -m vllm.entrypoints.openai.api_server \
|
||||||
|
--model /root/autodl-tmp/DeepSeek-R1-1.5B \
|
||||||
|
--served-model-name deepseek-r1 \
|
||||||
|
--tensor-parallel-size 1 \
|
||||||
|
--max-model-len 131072 \
|
||||||
|
--gpu-memory-utilization 0.95 \
|
||||||
|
--port 6006'
|
||||||
|
|
||||||
|
screen -U -L -Logfile /root/vllm_server.log -dmS vllm_server bash -c 'python -m vllm.entrypoints.openai.api_server \
|
||||||
|
--model /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-7B \
|
||||||
|
--served-model-name deepseek-r1 \
|
||||||
|
--tensor-parallel-size 1 \
|
||||||
|
--max-model-len 131072 \
|
||||||
|
--gpu-memory-utilization 0.95 \
|
||||||
|
--port 6006'
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
可以决定
|
||||||
|
--reasoning-parser deepseek_r1
|
||||||
|
```
|
||||||
|
|
||||||
|
**参数解释:**
|
||||||
|
|
||||||
|
- `--max-model-len 8192`:限制最大上下文为 8K token(因为模型本身 64G,A800 剩约 15G 显存留给 KV Cache,8K 是比较安全且不会 OOM 的长度)。
|
||||||
|
- `--gpu-memory-utilization 0.95`:允许 vLLM 使用 95% 的显存。
|
||||||
|
- `--served-model-name`:客户端调用时填写的模型名称。
|
||||||
|
|
||||||
|
等待终端显示 `Uvicorn running on http://0.0.0.0:6006` 字样,即代表部署成功。
|
||||||
|
|
||||||
|
# 第四步:测试调用 (与 OpenAI API 完全兼容)
|
||||||
|
|
||||||
|
您可以在同一个实例新开一个终端,或者直接在当前终端输入以下命令进行测试:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl http://localhost:6006/v1/chat/completions \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"messages":[
|
||||||
|
{"role": "system", "content": "你是一个有用的AI助手。"},
|
||||||
|
{"role": "user", "content": "请用Python写一个快速排序算法。"}
|
||||||
|
],
|
||||||
|
"max_tokens": 1024,
|
||||||
|
"temperature": 0.6
|
||||||
|
}'
|
||||||
|
```
|
||||||
@@ -0,0 +1,883 @@
|
|||||||
|
## 安装命令
|
||||||
|
|
||||||
|
如何实现离线安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
pip install vllm
|
||||||
|
pip download -d /tmp/vllm_pkgs vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
root@autodl-container-c6d54aa471-4479d4d0:~# pip show vllm
|
||||||
|
Name: vllm
|
||||||
|
Version: 0.18.0
|
||||||
|
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
|
||||||
|
Home-page:
|
||||||
|
Author: vLLM Team
|
||||||
|
Author-email:
|
||||||
|
License:
|
||||||
|
Location: /root/miniconda3/lib/python3.12/site-packages
|
||||||
|
Requires: aiohttp, anthropic, blake3, cachetools, cbor2, cloudpickle, compressed-tensors, depyf, diskcache, einops, fastapi, filelock, flashinfer-python, gguf, ijson, lark, llguidance, lm-format-enforcer, mcp, mistral_common, model-hosting-container-standards, msgspec, ninja, numba, numpy, nvidia-cudnn-frontend, nvidia-cutlass-dsl, openai, openai-harmony, opencv-python-headless, opentelemetry-api, opentelemetry-exporter-otlp, opentelemetry-sdk, opentelemetry-semantic-conventions-ai, outlines_core, partial-json-parser, pillow, prometheus-fastapi-instrumentator, prometheus_client, protobuf, psutil, py-cpuinfo, pybase64, pydantic, python-json-logger, pyyaml, pyzmq, quack-kernels, regex, requests, sentencepiece, setproctitle, setuptools, six, tiktoken, tokenizers, torch, torchaudio, torchvision, tqdm, transformers, typing_extensions, watchfiles, xgrammar
|
||||||
|
Required-by:
|
||||||
|
```
|
||||||
|
|
||||||
|
一些建议:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create -n vllm python=3.12 -y
|
||||||
|
conda activate vllm
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装日志
|
||||||
|
|
||||||
|
```
|
||||||
|
root@autodl-container-c6d54aa471-4479d4d0:~/autodl-tmp# pip install vllm
|
||||||
|
Looking in indexes: http://mirrors.aliyun.com/pypi/simple
|
||||||
|
Collecting vllm
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/4f/e9/59cf9b8939b51e859d2166ac3336b353f52ec4f9ceda34228aae7b386840/vllm-0.18.0-cp38-abi3-manylinux_2_31_x86_64.whl (433.2 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 433.2/433.2 MB 7.0 MB/s eta 0:00:00
|
||||||
|
Collecting regex (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/9e/40/bb226f203caa22c1043c1ca79b36340156eca0f6a6742b46c3bb222a3a57/regex-2026.2.28-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (802 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 802.0/802.0 kB 13.3 MB/s eta 0:00:00
|
||||||
|
Collecting cachetools (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/06/f3/39cf3367b8107baa44f861dc802cbf16263c945b62d8265d36034fc07bea/cachetools-7.0.5-py3-none-any.whl (13 kB)
|
||||||
|
Requirement already satisfied: psutil in /root/miniconda3/lib/python3.12/site-packages (from vllm) (7.0.0)
|
||||||
|
Collecting sentencepiece (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/04/88/14f2f4a2b922d8b39be45bf63d79e6cd3a9b2f248b2fcb98a69b12af12f5/sentencepiece-0.2.1-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (1.4 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.4/1.4 MB 11.1 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: numpy in /root/miniconda3/lib/python3.12/site-packages (from vllm) (2.3.2)
|
||||||
|
Requirement already satisfied: requests>=2.26.0 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (2.31.0)
|
||||||
|
Requirement already satisfied: tqdm in /root/miniconda3/lib/python3.12/site-packages (from vllm) (4.66.2)
|
||||||
|
Collecting blake3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5b/94/eafaa5cdddadc0c9c603a6a6d8339433475e1a9f60c8bb9c2eed2d8736b6/blake3-1.0.8-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (388 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 388.0/388.0 kB 30.7 MB/s eta 0:00:00
|
||||||
|
Collecting py-cpuinfo (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/e0/a9/023730ba63db1e494a271cb018dcd361bd2c917ba7004c3e49d5daf795a2/py_cpuinfo-9.0.0-py3-none-any.whl (22 kB)
|
||||||
|
Collecting transformers<5,>=4.56.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/03/b8/e484ef633af3887baeeb4b6ad12743363af7cce68ae51e938e00aaa0529d/transformers-4.57.6-py3-none-any.whl (12.0 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.0/12.0 MB 9.5 MB/s eta 0:00:00
|
||||||
|
Collecting tokenizers>=0.21.1 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/2e/76/932be4b50ef6ccedf9d3c6639b056a967a86258c6d9200643f01269211ca/tokenizers-0.22.2-cp39-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.3 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.3/3.3 MB 10.6 MB/s eta 0:00:00
|
||||||
|
Collecting protobuf!=6.30.*,!=6.31.*,!=6.32.*,!=6.33.0.*,!=6.33.1.*,!=6.33.2.*,!=6.33.3.*,!=6.33.4.*,>=5.29.6 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/53/1b/3b431694a4dc6d37b9f653f0c64b0a0d9ec074ee810710c0c3da21d67ba7/protobuf-7.34.1-cp310-abi3-manylinux2014_x86_64.whl (324 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 324.3/324.3 kB 32.1 MB/s eta 0:00:00
|
||||||
|
Collecting fastapi>=0.115.0 (from fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/8f/ea/18f6d0457f9efb2fc6fa594857f92810cadb03024975726db6546b3d6fcf/fastapi-0.135.2-py3-none-any.whl (117 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 117.4/117.4 kB 31.5 MB/s eta 0:00:00
|
||||||
|
Collecting aiohttp>=3.13.3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/86/f6/a62cbbf13f0ac80a70f71b1672feba90fdb21fd7abd8dbf25c0105fb6fa3/aiohttp-3.13.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (1.8 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 11.9 MB/s eta 0:00:00
|
||||||
|
Collecting openai<2.25.0,>=1.99.1 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c9/30/844dc675ee6902579b8eef01ed23917cc9319a1c9c0c14ec6e39340c96d0/openai-2.24.0-py3-none-any.whl (1.1 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 6.8 MB/s eta 0:00:00
|
||||||
|
Collecting pydantic>=2.12.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5a/87/b70ad306ebb6f9b585f114d0ac2137d792b48be34d732d60e597c2f8465a/pydantic-2.12.5-py3-none-any.whl (463 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 463.6/463.6 kB 12.2 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: prometheus_client>=0.18.0 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (0.22.1)
|
||||||
|
Requirement already satisfied: pillow in /root/miniconda3/lib/python3.12/site-packages (from vllm) (11.3.0)
|
||||||
|
Collecting prometheus-fastapi-instrumentator>=7.0.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/27/72/0824c18f3bc75810f55dacc2dd933f6ec829771180245ae3cc976195dec0/prometheus_fastapi_instrumentator-7.1.0-py3-none-any.whl (19 kB)
|
||||||
|
Collecting tiktoken>=0.6.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/f4/90/3dae6cc5436137ebd38944d396b5849e167896fc2073da643a49f372dc4f/tiktoken-0.12.0-cp312-cp312-manylinux_2_28_x86_64.whl (1.2 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.2/1.2 MB 14.4 MB/s eta 0:00:00
|
||||||
|
Collecting lm-format-enforcer==0.11.3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a0/ef/11292bb0b85cf4c93447cab5a29f64576ed14d3ab4280e35ddd23486594a/lm_format_enforcer-0.11.3-py3-none-any.whl (45 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 45.4/45.4 kB 21.0 MB/s eta 0:00:00
|
||||||
|
Collecting llguidance<1.4.0,>=1.3.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/83/a8/1ff2bedb8f9acb46a2d2d603415d272bb622c142ea86f5b95445cc6e366c/llguidance-1.3.0-cp39-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.0 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.0/3.0 MB 11.0 MB/s eta 0:00:00
|
||||||
|
Collecting outlines_core==0.2.11 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/92/c7/a65d1fddf49830ebc41422294eacde35286d9f68994a8aa905cb14f5aade/outlines_core-0.2.11-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.3 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.3/2.3 MB 12.9 MB/s eta 0:00:00
|
||||||
|
Collecting diskcache==5.6.3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/3f/27/4570e78fc0bf5ea0ca45eb1de3818a23787af9b390c0b0a0033a1b8236f9/diskcache-5.6.3-py3-none-any.whl (45 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 45.5/45.5 kB 16.4 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: lark==1.2.2 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (1.2.2)
|
||||||
|
Collecting xgrammar<1.0.0,>=0.1.32 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/69/62/65e664d861cdadf2d788c03dd8fe67f1faaa7bd4bd2317a2ab850aebee20/xgrammar-0.1.32-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (37.7 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 37.7/37.7 MB 11.5 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: typing_extensions>=4.10 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (4.14.1)
|
||||||
|
Requirement already satisfied: filelock>=3.16.1 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (3.18.0)
|
||||||
|
Collecting partial-json-parser (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/42/32/658973117bf0fd82a24abbfb94fe73a5e86216e49342985e10acce54775a/partial_json_parser-0.2.1.1.post7-py3-none-any.whl (10 kB)
|
||||||
|
Requirement already satisfied: pyzmq>=25.0.0 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (27.0.1)
|
||||||
|
Collecting msgspec (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5c/a2/488517a43ccf5a4b6b6eca6dd4ede0bd82b043d1539dd6bb908a19f8efd3/msgspec-0.20.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (224 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 224.9/224.9 kB 44.8 MB/s eta 0:00:00
|
||||||
|
Collecting gguf>=0.17.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5e/0c/e0f1eae7535a97476fb903f65301e35da2a66182b8161066b7eb312b2cb8/gguf-0.18.0-py3-none-any.whl (114 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 114.2/114.2 kB 45.5 MB/s eta 0:00:00
|
||||||
|
Collecting mistral_common>=1.10.0 (from mistral_common[image]>=1.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/87/c6/1429a0a3ab40f8530492b62b52eb792266c261b22ed62aa7f25d61d531ae/mistral_common-1.10.0-py3-none-any.whl (6.5 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.5/6.5 MB 9.6 MB/s eta 0:00:00
|
||||||
|
Collecting opencv-python-headless>=4.13.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/4b/33/b5db29a6c00eb8f50708110d8d453747ca125c8b805bc437b289dbdcc057/opencv_python_headless-4.13.0.92-cp37-abi3-manylinux_2_28_x86_64.whl (60.4 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 60.4/60.4 MB 10.7 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: pyyaml in /root/miniconda3/lib/python3.12/site-packages (from vllm) (6.0.2)
|
||||||
|
Requirement already satisfied: six>=1.16.0 in /root/miniconda3/lib/python3.12/site-packages (from vllm) (1.17.0)
|
||||||
|
Collecting setuptools<81.0.0,>=77.0.3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/94/b8/f1f62a5e3c0ad2ff1d189590bfa4c46b4f3b6e49cef6f26c6ee4e575394d/setuptools-80.10.2-py3-none-any.whl (1.1 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 14.2 MB/s eta 0:00:00
|
||||||
|
Collecting einops (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/2a/09/f8d8f8f31e4483c10a906437b4ce31bdf3d6d417b73fe33f1a8b59e34228/einops-0.8.2-py3-none-any.whl (65 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 65.6/65.6 kB 26.7 MB/s eta 0:00:00
|
||||||
|
Collecting compressed-tensors==0.13.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0b/b5/61ac2563c62490922b603c09113a083fd74af3630ec3931e769484d6dcb5/compressed_tensors-0.13.0-py3-none-any.whl (192 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 192.6/192.6 kB 42.8 MB/s eta 0:00:00
|
||||||
|
Collecting depyf==0.20.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/cf/65/4df6936130b56e1429114e663e7c1576cf845f3aef1b2dd200c0a5d19dba/depyf-0.20.0-py3-none-any.whl (39 kB)
|
||||||
|
Collecting cloudpickle (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/88/39/799be3f2f0f38cc727ee3b4f1445fe6d5e4133064ec2e4115069418a5bb6/cloudpickle-3.1.2-py3-none-any.whl (22 kB)
|
||||||
|
Collecting watchfiles (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/cf/68/5707da262a119fb06fbe214d82dd1fe4a6f4af32d2d14de368d0349eb52a/watchfiles-1.1.1-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (456 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 456.8/456.8 kB 40.0 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: python-json-logger in /root/miniconda3/lib/python3.12/site-packages (from vllm) (3.3.0)
|
||||||
|
Collecting ninja (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/ed/de/0e6edf44d6a04dabd0318a519125ed0415ce437ad5a1ec9b9be03d9048cf/ninja-1.13.0-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (180 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 180.7/180.7 kB 39.5 MB/s eta 0:00:00
|
||||||
|
Collecting pybase64 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/62/f7/965b79ff391ad208b50e412b5d3205ccce372a2d27b7218ae86d5295b105/pybase64-1.4.3-cp312-cp312-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl (71 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 71.6/71.6 kB 36.8 MB/s eta 0:00:00
|
||||||
|
Collecting cbor2 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/db/9d/7ede2cc42f9bb4260492e7d29d2aab781eacbbcfb09d983de1e695077199/cbor2-5.9.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (288 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 288.2/288.2 kB 19.8 MB/s eta 0:00:00
|
||||||
|
Collecting ijson (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/6d/81/2fee58f9024a3449aee83edfa7167fb5ccd7e1af2557300e28531bb68e16/ijson-3.5.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (149 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 149.7/149.7 kB 28.8 MB/s eta 0:00:00
|
||||||
|
Collecting setproctitle (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/d0/99/71630546b9395b095f4082be41165d1078204d1696c2d9baade3de3202d0/setproctitle-1.3.7-cp312-cp312-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl (32 kB)
|
||||||
|
Collecting openai-harmony>=0.0.3 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/25/3f/1a192b93bb47c6b44cd98ba8cc1d3d2a9308f1bb700c3017e6352da11bda/openai_harmony-0.0.8-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.0 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.0/3.0 MB 11.9 MB/s eta 0:00:00
|
||||||
|
Collecting anthropic>=0.71.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/63/5f/67db29c6e5d16c8c9c4652d3efb934d89cb750cad201539141781d8eae14/anthropic-0.86.0-py3-none-any.whl (469 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 469.4/469.4 kB 27.6 MB/s eta 0:00:00
|
||||||
|
Collecting model-hosting-container-standards<1.0.0,>=0.1.13 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/48/94/052452842d39c562237a70345c57ec213a9db22bd25bba998fd2b32d70a7/model_hosting_container_standards-0.1.14-py3-none-any.whl (121 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 121.4/121.4 kB 32.0 MB/s eta 0:00:00
|
||||||
|
Collecting mcp (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/fd/d9/eaa1f80170d2b7c5ba23f3b59f766f3a0bb41155fbc32a69adfa1adaaef9/mcp-1.26.0-py3-none-any.whl (233 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 233.6/233.6 kB 28.6 MB/s eta 0:00:00
|
||||||
|
Collecting opentelemetry-sdk>=1.27.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/2c/c5/6a852903d8bfac758c6dc6e9a68b015d3c33f2f1be5e9591e0f4b69c7e0a/opentelemetry_sdk-1.40.0-py3-none-any.whl (141 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 142.0/142.0 kB 32.3 MB/s eta 0:00:00
|
||||||
|
Collecting opentelemetry-api>=1.27.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5f/bf/93795954016c522008da367da292adceed71cca6ee1717e1d64c83089099/opentelemetry_api-1.40.0-py3-none-any.whl (68 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 68.7/68.7 kB 32.4 MB/s eta 0:00:00
|
||||||
|
Collecting opentelemetry-exporter-otlp>=1.27.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/2d/fc/aea77c28d9f3ffef2fdafdc3f4a235aee4091d262ddabd25882f47ce5c5f/opentelemetry_exporter_otlp-1.40.0-py3-none-any.whl (7.0 kB)
|
||||||
|
Collecting opentelemetry-semantic-conventions-ai>=0.4.1 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a7/18/35fec29ed6e49bcbbe629b790cc0deb5bb58da9caceee29b39b54d3d7f47/opentelemetry_semantic_conventions_ai-0.5.0-py3-none-any.whl (10.0 kB)
|
||||||
|
Collecting numba==0.61.2 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/9a/2d/e518df036feab381c23a624dac47f8445ac55686ec7f11083655eb707da3/numba-0.61.2-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (3.9 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 10.1 MB/s eta 0:00:00
|
||||||
|
Collecting torch==2.10.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/b3/7a/abada41517ce0011775f0f4eacc79659bc9bc6c361e6bfe6f7052a6b9363/torch-2.10.0-3-cp312-cp312-manylinux_2_28_x86_64.whl (915.6 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 915.6/915.6 MB 4.6 MB/s eta 0:00:00
|
||||||
|
Collecting torchaudio==2.10.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/98/25/e55a30d7138f8fe56ed006df25b0a3c27681f0ec7bc9989e1778e6d559c3/torchaudio-2.10.0-cp312-cp312-manylinux_2_28_x86_64.whl (1.9 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.9/1.9 MB 14.1 MB/s eta 0:00:00
|
||||||
|
Collecting torchvision==0.25.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/68/2f/f24b039169db474e8688f649377de082a965fbf85daf4e46c44412f1d15a/torchvision-0.25.0-cp312-cp312-manylinux_2_28_x86_64.whl (8.1 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.1/8.1 MB 10.9 MB/s eta 0:00:00
|
||||||
|
Collecting flashinfer-python==0.6.6 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/e0/61/385d06755f3ab66333018285657adf0daf8a90a129448231fd09e315bd2e/flashinfer_python-0.6.6-py3-none-any.whl (7.8 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 11.1 MB/s eta 0:00:00
|
||||||
|
Collecting nvidia-cudnn-frontend<1.19.0,>=1.13.0 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c6/52/08f98262e77b1cbcc834cc1a5db494d0661ea1dbdea58c2e2d51a57fdaca/nvidia_cudnn_frontend-1.18.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (2.2 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.2/2.2 MB 13.7 MB/s eta 0:00:00
|
||||||
|
Collecting nvidia-cutlass-dsl>=4.4.0.dev1 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a9/03/678dab0383db1ddfc449da216220f40404189eb36eeed9d87a4fa4bdb0e6/nvidia_cutlass_dsl-4.4.2-py3-none-any.whl (10 kB)
|
||||||
|
Collecting quack-kernels>=0.2.7 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/45/e6/fb900aa5d6053069c3180382874520e7313362fa03994a034626906e7094/quack_kernels-0.3.5-py3-none-any.whl (195 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 195.7/195.7 kB 28.3 MB/s eta 0:00:00
|
||||||
|
Collecting loguru (from compressed-tensors==0.13.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0c/29/0348de65b8cc732daa3e33e67806420b2ae89bdce2b04af740289c5c6c8c/loguru-0.7.3-py3-none-any.whl (61 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.6/61.6 kB 33.3 MB/s eta 0:00:00
|
||||||
|
Collecting astor (from depyf==0.20.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c3/88/97eef84f48fa04fbd6750e62dcceafba6c63c81b7ac1420856c8dcc0a3f9/astor-0.8.1-py2.py3-none-any.whl (27 kB)
|
||||||
|
Collecting dill (from depyf==0.20.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/1e/77/dc8c558f7593132cf8fefec57c4f60c83b16941c574ac5f619abb3ae7933/dill-0.4.1-py3-none-any.whl (120 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 120.0/120.0 kB 2.4 MB/s eta 0:00:00
|
||||||
|
Collecting apache-tvm-ffi!=0.1.8,!=0.1.8.post0,<0.2,>=0.1.6 (from flashinfer-python==0.6.6->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/70/ef/5402da5d37f5270fd88ea0348acca78dba9be8bdbf6c2bcae0935eb03ef1/apache_tvm_ffi-0.1.9-cp312-abi3-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl (2.3 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.3/2.3 MB 10.0 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: click in /root/miniconda3/lib/python3.12/site-packages (from flashinfer-python==0.6.6->vllm) (8.3.1)
|
||||||
|
Collecting nvidia-ml-py (from flashinfer-python==0.6.6->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/8a/24/fc256107d23597fa33d319505ce77160fa1a2349c096d01901ffc7cb7fc4/nvidia_ml_py-13.595.45-py3-none-any.whl (51 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 51.8/51.8 kB 23.7 MB/s eta 0:00:00
|
||||||
|
Collecting packaging>=24.2 (from flashinfer-python==0.6.6->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/b7/b9/c538f279a4e237a006a2c98387d081e9eb060d203d8ed34467cc0f0b9b53/packaging-26.0-py3-none-any.whl (74 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 74.4/74.4 kB 32.2 MB/s eta 0:00:00
|
||||||
|
Collecting tabulate (from flashinfer-python==0.6.6->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/99/55/db07de81b5c630da5cbf5c7df646580ca26dfaefa593667fc6f2fe016d2e/tabulate-0.10.0-py3-none-any.whl (39 kB)
|
||||||
|
Collecting interegular>=0.3.2 (from lm-format-enforcer==0.11.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c4/01/72d6472f80651673716d1deda2a5bbb633e563ecf94f4479da5519d69d25/interegular-0.3.3-py37-none-any.whl (23 kB)
|
||||||
|
Collecting llvmlite<0.45,>=0.44.0dev0 (from numba==0.61.2->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/cb/da/8341fd3056419441286c8e26bf436923021005ece0bff5f41906476ae514/llvmlite-0.44.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (42.4 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 42.4/42.4 MB 9.8 MB/s eta 0:00:00
|
||||||
|
Collecting numpy (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/8c/3d/1e1db36cfd41f895d266b103df00ca5b3cbe965184df824dec5c08c6b803/numpy-2.2.6-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (16.5 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 16.5/16.5 MB 10.4 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: sympy>=1.13.3 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (1.14.0)
|
||||||
|
Requirement already satisfied: networkx>=2.5.1 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (3.5)
|
||||||
|
Requirement already satisfied: jinja2 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (3.1.6)
|
||||||
|
Requirement already satisfied: fsspec>=0.8.5 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (2025.7.0)
|
||||||
|
Collecting cuda-bindings==12.9.4 (from torch==2.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a9/c1/dabe88f52c3e3760d861401bb994df08f672ec893b8f7592dc91626adcf3/cuda_bindings-12.9.4-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl (12.2 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.2/12.2 MB 10.3 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.8.93 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.93)
|
||||||
|
Requirement already satisfied: nvidia-cuda-runtime-cu12==12.8.90 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.90)
|
||||||
|
Requirement already satisfied: nvidia-cuda-cupti-cu12==12.8.90 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.90)
|
||||||
|
Requirement already satisfied: nvidia-cudnn-cu12==9.10.2.21 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (9.10.2.21)
|
||||||
|
Requirement already satisfied: nvidia-cublas-cu12==12.8.4.1 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.4.1)
|
||||||
|
Requirement already satisfied: nvidia-cufft-cu12==11.3.3.83 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (11.3.3.83)
|
||||||
|
Requirement already satisfied: nvidia-curand-cu12==10.3.9.90 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (10.3.9.90)
|
||||||
|
Requirement already satisfied: nvidia-cusolver-cu12==11.7.3.90 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (11.7.3.90)
|
||||||
|
Requirement already satisfied: nvidia-cusparse-cu12==12.5.8.93 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.5.8.93)
|
||||||
|
Requirement already satisfied: nvidia-cusparselt-cu12==0.7.1 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (0.7.1)
|
||||||
|
Collecting nvidia-nccl-cu12==2.27.5 (from torch==2.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/6e/89/f7a07dc961b60645dbbf42e80f2bc85ade7feb9a491b11a1e973aa00071f/nvidia_nccl_cu12-2.27.5-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (322.3 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 322.3/322.3 MB 7.1 MB/s eta 0:00:00
|
||||||
|
Collecting nvidia-nvshmem-cu12==3.4.5 (from torch==2.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/b5/09/6ea3ea725f82e1e76684f0708bbedd871fc96da89945adeba65c3835a64c/nvidia_nvshmem_cu12-3.4.5-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl (139.1 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 139.1/139.1 MB 8.9 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: nvidia-nvtx-cu12==12.8.90 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.90)
|
||||||
|
Requirement already satisfied: nvidia-nvjitlink-cu12==12.8.93 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (12.8.93)
|
||||||
|
Requirement already satisfied: nvidia-cufile-cu12==1.13.1.3 in /root/miniconda3/lib/python3.12/site-packages (from torch==2.10.0->vllm) (1.13.1.3)
|
||||||
|
Collecting triton==3.6.0 (from torch==2.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/ab/a8/cdf8b3e4c98132f965f88c2313a4b493266832ad47fb52f23d14d4f86bb5/triton-3.6.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl (188.3 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 188.3/188.3 MB 8.1 MB/s eta 0:00:00
|
||||||
|
Collecting cuda-pathfinder~=1.1 (from cuda-bindings==12.9.4->torch==2.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c0/66/7b2c3d23dac4bb9629b4d9702f1f796bd41c01142c2b47be6fcfdeaf4ee4/cuda_pathfinder-1.4.4-py3-none-any.whl (48 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 48.8/48.8 kB 18.4 MB/s eta 0:00:00
|
||||||
|
Collecting aiohappyeyeballs>=2.5.0 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0f/15/5bf3b99495fb160b63f95972b81750f18f7f4e02ad051373b669d17d44f2/aiohappyeyeballs-2.6.1-py3-none-any.whl (15 kB)
|
||||||
|
Collecting aiosignal>=1.4.0 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/fb/76/641ae371508676492379f16e2fa48f4e2c11741bd63c48be4b12a6b09cba/aiosignal-1.4.0-py3-none-any.whl (7.5 kB)
|
||||||
|
Requirement already satisfied: attrs>=17.3.0 in /root/miniconda3/lib/python3.12/site-packages (from aiohttp>=3.13.3->vllm) (25.3.0)
|
||||||
|
Collecting frozenlist>=1.1.1 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/6a/bd/d91c5e39f490a49df14320f4e8c80161cfcce09f1e2cde1edd16a551abb3/frozenlist-1.8.0-cp312-cp312-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl (242 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 242.4/242.4 kB 4.8 MB/s eta 0:00:00
|
||||||
|
Collecting multidict<7.0,>=4.5 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/f3/8d/5e5be3ced1d12966fefb5c4ea3b2a5b480afcea36406559442c6e31d4a48/multidict-6.7.1-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (256 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 256.3/256.3 kB 14.4 MB/s eta 0:00:00
|
||||||
|
Collecting propcache>=0.2.0 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/46/4b/3aae6835b8e5f44ea6a68348ad90f78134047b503765087be2f9912140ea/propcache-0.4.1-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (221 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 221.6/221.6 kB 17.2 MB/s eta 0:00:00
|
||||||
|
Collecting yarl<2.0,>=1.17.0 (from aiohttp>=3.13.3->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/66/3e/868e5c3364b6cee19ff3e1a122194fa4ce51def02c61023970442162859e/yarl-1.23.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (100 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.1/100.1 kB 15.2 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: anyio<5,>=3.5.0 in /root/miniconda3/lib/python3.12/site-packages (from anthropic>=0.71.0->vllm) (4.10.0)
|
||||||
|
Requirement already satisfied: distro<2,>=1.7.0 in /root/miniconda3/lib/python3.12/site-packages (from anthropic>=0.71.0->vllm) (1.9.0)
|
||||||
|
Collecting docstring-parser<1,>=0.15 (from anthropic>=0.71.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/55/e2/2537ebcff11c1ee1ff17d8d0b6f4db75873e3b0fb32c2d4a2ee31ecb310a/docstring_parser-0.17.0-py3-none-any.whl (36 kB)
|
||||||
|
Requirement already satisfied: httpx<1,>=0.25.0 in /root/miniconda3/lib/python3.12/site-packages (from anthropic>=0.71.0->vllm) (0.28.1)
|
||||||
|
Collecting jiter<1,>=0.4.0 (from anthropic>=0.71.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/f8/4c/09b93e30e984a187bc8aaa3510e1ec8dcbdcd71ca05d2f56aac0492453aa/jiter-0.13.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (360 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 360.7/360.7 kB 16.4 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: sniffio in /root/miniconda3/lib/python3.12/site-packages (from anthropic>=0.71.0->vllm) (1.3.1)
|
||||||
|
Collecting starlette>=0.46.0 (from fastapi>=0.115.0->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0b/c9/584bc9651441b4ba60cc4d557d8a547b5aff901af35bda3a4ee30c819b82/starlette-1.0.0-py3-none-any.whl (72 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 72.7/72.7 kB 15.4 MB/s eta 0:00:00
|
||||||
|
Collecting typing-inspection>=0.4.2 (from fastapi>=0.115.0->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/dc/9b/47798a6c91d8bdb567fe2698fe81e0c6b7cb7ef4d13da4114b41d239f65d/typing_inspection-0.4.2-py3-none-any.whl (14 kB)
|
||||||
|
Requirement already satisfied: annotated-doc>=0.0.2 in /root/miniconda3/lib/python3.12/site-packages (from fastapi>=0.115.0->fastapi[standard]>=0.115.0->vllm) (0.0.4)
|
||||||
|
Collecting fastapi-cli>=0.0.8 (from fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/c7/4b/68f9fe268e535d79c76910519530026a4f994ce07189ac0dded45c6af825/fastapi_cli-0.0.24-py3-none-any.whl (12 kB)
|
||||||
|
Collecting python-multipart>=0.0.18 (from fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/1b/d0/397f9626e711ff749a95d96b7af99b9c566a9bb5129b8e4c10fc4d100304/python_multipart-0.0.22-py3-none-any.whl (24 kB)
|
||||||
|
Collecting email-validator>=2.0.0 (from fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/de/15/545e2b6cf2e3be84bc1ed85613edd75b8aea69807a71c26f4ca6a9258e82/email_validator-2.3.0-py3-none-any.whl (35 kB)
|
||||||
|
Collecting uvicorn>=0.12.0 (from uvicorn[standard]>=0.12.0; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0a/89/f8827ccff89c1586027a105e5630ff6139a64da2515e24dafe860bd9ae4d/uvicorn-0.42.0-py3-none-any.whl (68 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 68.8/68.8 kB 16.4 MB/s eta 0:00:00
|
||||||
|
Collecting pydantic-settings>=2.0.0 (from fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/00/4b/ccc026168948fec4f7555b9164c724cf4125eac006e176541483d2c959be/pydantic_settings-2.13.1-py3-none-any.whl (58 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.9/58.9 kB 18.5 MB/s eta 0:00:00
|
||||||
|
Collecting pydantic-extra-types>=2.0.0 (from fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/17/c1/3226e6d7f5a4f736f38ac11a6fbb262d701889802595cdb0f53a885ac2e0/pydantic_extra_types-2.11.1-py3-none-any.whl (79 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 79.5/79.5 kB 25.0 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: jsonschema>=4.21.1 in /root/miniconda3/lib/python3.12/site-packages (from mistral_common>=1.10.0->mistral_common[image]>=1.10.0->vllm) (4.25.0)
|
||||||
|
Collecting jmespath (from model-hosting-container-standards<1.0.0,>=0.1.13->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/14/2f/967ba146e6d58cf6a652da73885f52fc68001525b4197effc174321d70b4/jmespath-1.1.0-py3-none-any.whl (20 kB)
|
||||||
|
Requirement already satisfied: supervisor>=4.2.0 in /root/miniconda3/lib/python3.12/site-packages (from model-hosting-container-standards<1.0.0,>=0.1.13->vllm) (4.2.5)
|
||||||
|
Collecting nvidia-cutlass-dsl-libs-base==4.4.2 (from nvidia-cutlass-dsl>=4.4.0.dev1->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/56/98/e264964741d9cc9816625d9600d17a5249fd5cbd8c2d166fb0d0c34dfe5a/nvidia_cutlass_dsl_libs_base-4.4.2-cp312-cp312-manylinux_2_28_x86_64.whl (74.4 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 74.4/74.4 MB 8.7 MB/s eta 0:00:00
|
||||||
|
Collecting cuda-python>=12.8 (from nvidia-cutlass-dsl-libs-base==4.4.2->nvidia-cutlass-dsl>=4.4.0.dev1->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/4a/da/b4dbe129f941afe1c24a09ba53521b78875626763d96414798a74763282f/cuda_python-13.2.0-py3-none-any.whl (8.1 kB)
|
||||||
|
Collecting importlib-metadata<8.8.0,>=6.0 (from opentelemetry-api>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/fa/5e/f8e9a1d23b9c20a551a8a02ea3637b4642e22c2626e3a13a9a29cdea99eb/importlib_metadata-8.7.1-py3-none-any.whl (27 kB)
|
||||||
|
Collecting opentelemetry-exporter-otlp-proto-grpc==1.40.0 (from opentelemetry-exporter-otlp>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/96/6f/7ee0980afcbdcd2d40362da16f7f9796bd083bf7f0b8e038abfbc0300f5d/opentelemetry_exporter_otlp_proto_grpc-1.40.0-py3-none-any.whl (20 kB)
|
||||||
|
Collecting opentelemetry-exporter-otlp-proto-http==1.40.0 (from opentelemetry-exporter-otlp>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a0/3a/8865d6754e61c9fb170cdd530a124a53769ee5f740236064816eb0ca7301/opentelemetry_exporter_otlp_proto_http-1.40.0-py3-none-any.whl (19 kB)
|
||||||
|
Collecting googleapis-common-protos~=1.57 (from opentelemetry-exporter-otlp-proto-grpc==1.40.0->opentelemetry-exporter-otlp>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/69/28/23eea8acd65972bbfe295ce3666b28ac510dfcb115fac089d3edb0feb00a/googleapis_common_protos-1.73.0-py3-none-any.whl (297 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 297.6/297.6 kB 15.8 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: grpcio<2.0.0,>=1.63.2 in /root/miniconda3/lib/python3.12/site-packages (from opentelemetry-exporter-otlp-proto-grpc==1.40.0->opentelemetry-exporter-otlp>=1.27.0->vllm) (1.74.0)
|
||||||
|
Collecting opentelemetry-exporter-otlp-proto-common==1.40.0 (from opentelemetry-exporter-otlp-proto-grpc==1.40.0->opentelemetry-exporter-otlp>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/8b/ca/8f122055c97a932311a3f640273f084e738008933503d0c2563cd5d591fc/opentelemetry_exporter_otlp_proto_common-1.40.0-py3-none-any.whl (18 kB)
|
||||||
|
Collecting opentelemetry-proto==1.40.0 (from opentelemetry-exporter-otlp-proto-grpc==1.40.0->opentelemetry-exporter-otlp>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/b9/b2/189b2577dde745b15625b3214302605b1353436219d42b7912e77fa8dc24/opentelemetry_proto-1.40.0-py3-none-any.whl (72 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 72.1/72.1 kB 14.7 MB/s eta 0:00:00
|
||||||
|
Collecting protobuf!=6.30.*,!=6.31.*,!=6.32.*,!=6.33.0.*,!=6.33.1.*,!=6.33.2.*,!=6.33.3.*,!=6.33.4.*,>=5.29.6 (from vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/16/92/d1e32e3e0d894fe00b15ce28ad4944ab692713f2e7f0a99787405e43533a/protobuf-6.33.6-cp39-abi3-manylinux2014_x86_64.whl (323 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 323.4/323.4 kB 15.5 MB/s eta 0:00:00
|
||||||
|
Collecting opentelemetry-semantic-conventions==0.61b0 (from opentelemetry-sdk>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/b2/37/cc6a55e448deaa9b27377d087da8615a3416d8ad523d5960b78dbeadd02a/opentelemetry_semantic_conventions-0.61b0-py3-none-any.whl (231 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 231.6/231.6 kB 16.4 MB/s eta 0:00:00
|
||||||
|
Collecting starlette>=0.46.0 (from fastapi>=0.115.0->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/81/0d/13d1d239a25cbfb19e740db83143e95c772a1fe10202dda4b76792b114dd/starlette-0.52.1-py3-none-any.whl (74 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 74.3/74.3 kB 16.1 MB/s eta 0:00:00
|
||||||
|
Collecting annotated-types>=0.6.0 (from pydantic>=2.12.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/78/b6/6307fbef88d9b5ee7421e68d78a9f162e0da4900bc5f5793f6d3d0e34fb8/annotated_types-0.7.0-py3-none-any.whl (13 kB)
|
||||||
|
Collecting pydantic-core==2.41.5 (from pydantic>=2.12.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0d/76/941cc9f73529988688a665a5c0ecff1112b3d95ab48f81db5f7606f522d3/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.1 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 13.5 MB/s eta 0:00:00
|
||||||
|
Collecting torch-c-dlpack-ext (from quack-kernels>=0.2.7->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/e2/79/a914539b4785f3e44f891aa012a886edb8bc10fe081c440981c57543ce21/torch_c_dlpack_ext-0.1.5-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl (897 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 897.8/897.8 kB 17.5 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: charset-normalizer<4,>=2 in /root/miniconda3/lib/python3.12/site-packages (from requests>=2.26.0->vllm) (2.0.4)
|
||||||
|
Requirement already satisfied: idna<4,>=2.5 in /root/miniconda3/lib/python3.12/site-packages (from requests>=2.26.0->vllm) (3.7)
|
||||||
|
Requirement already satisfied: urllib3<3,>=1.21.1 in /root/miniconda3/lib/python3.12/site-packages (from requests>=2.26.0->vllm) (2.1.0)
|
||||||
|
Requirement already satisfied: certifi>=2017.4.17 in /root/miniconda3/lib/python3.12/site-packages (from requests>=2.26.0->vllm) (2024.2.2)
|
||||||
|
Requirement already satisfied: huggingface-hub<2.0,>=0.16.4 in /root/miniconda3/lib/python3.12/site-packages (from tokenizers>=0.21.1->vllm) (1.7.2)
|
||||||
|
Collecting huggingface-hub<2.0,>=0.16.4 (from tokenizers>=0.21.1->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a8/af/48ac8483240de756d2438c380746e7130d1c6f75802ef22f3c6d49982787/huggingface_hub-0.36.2-py3-none-any.whl (566 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 566.4/566.4 kB 13.5 MB/s eta 0:00:00
|
||||||
|
Collecting safetensors>=0.4.3 (from transformers<5,>=4.56.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/a0/60/429e9b1cb3fc651937727befe258ea24122d9663e4d5709a48c9cbfceecb/safetensors-0.7.0-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (507 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 507.2/507.2 kB 32.9 MB/s eta 0:00:00
|
||||||
|
Collecting httpx-sse>=0.4 (from mcp->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/d2/fd/6668e5aec43ab844de6fc74927e155a3b37bf40d7c3790e49fc0406b6578/httpx_sse-0.4.3-py3-none-any.whl (9.0 kB)
|
||||||
|
Collecting pyjwt>=2.10.1 (from pyjwt[crypto]>=2.10.1->mcp->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/e5/7a/8dd906bd22e79e47397a61742927f6747fe93242ef86645ee9092e610244/pyjwt-2.12.1-py3-none-any.whl (29 kB)
|
||||||
|
Collecting sse-starlette>=1.6.1 (from mcp->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/78/e2/b8cff57a67dddf9a464d7e943218e031617fb3ddc133aeeb0602ff5f6c85/sse_starlette-3.3.3-py3-none-any.whl (14 kB)
|
||||||
|
Collecting dnspython>=2.0.0 (from email-validator>=2.0.0->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/ba/5a/18ad964b0086c6e62e2e7500f7edc89e3faa45033c71c1893d34eed2b2de/dnspython-2.8.0-py3-none-any.whl (331 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 331.1/331.1 kB 33.9 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: typer>=0.16.0 in /root/miniconda3/lib/python3.12/site-packages (from fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (0.24.1)
|
||||||
|
Collecting rich-toolkit>=0.14.8 (from fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/fb/3c/c923619f6d2f5fafcc96fec0aaf9550a46cd5b6481f06e0c6b66a2a4fed0/rich_toolkit-0.19.7-py3-none-any.whl (32 kB)
|
||||||
|
Collecting fastapi-cloud-cli>=0.1.1 (from fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/40/cc/1ccca747f5609be27186ea8c9219449142f40e3eded2c6089bba6a6ecc82/fastapi_cloud_cli-0.15.0-py3-none-any.whl (32 kB)
|
||||||
|
Requirement already satisfied: httpcore==1.* in /root/miniconda3/lib/python3.12/site-packages (from httpx<1,>=0.25.0->anthropic>=0.71.0->vllm) (1.0.9)
|
||||||
|
Requirement already satisfied: h11>=0.16 in /root/miniconda3/lib/python3.12/site-packages (from httpcore==1.*->httpx<1,>=0.25.0->anthropic>=0.71.0->vllm) (0.16.0)
|
||||||
|
Requirement already satisfied: hf-xet<2.0.0,>=1.1.3 in /root/miniconda3/lib/python3.12/site-packages (from huggingface-hub<2.0,>=0.16.4->tokenizers>=0.21.1->vllm) (1.4.2)
|
||||||
|
Collecting zipp>=3.20 (from importlib-metadata<8.8.0,>=6.0->opentelemetry-api>=1.27.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/2e/54/647ade08bf0db230bfea292f893923872fd20be6ac6f53b2b936ba839d75/zipp-3.23.0-py3-none-any.whl (10 kB)
|
||||||
|
Requirement already satisfied: MarkupSafe>=2.0 in /root/miniconda3/lib/python3.12/site-packages (from jinja2->torch==2.10.0->vllm) (3.0.2)
|
||||||
|
Requirement already satisfied: jsonschema-specifications>=2023.03.6 in /root/miniconda3/lib/python3.12/site-packages (from jsonschema>=4.21.1->mistral_common>=1.10.0->mistral_common[image]>=1.10.0->vllm) (2025.4.1)
|
||||||
|
Requirement already satisfied: referencing>=0.28.4 in /root/miniconda3/lib/python3.12/site-packages (from jsonschema>=4.21.1->mistral_common>=1.10.0->mistral_common[image]>=1.10.0->vllm) (0.36.2)
|
||||||
|
Requirement already satisfied: rpds-py>=0.7.1 in /root/miniconda3/lib/python3.12/site-packages (from jsonschema>=4.21.1->mistral_common>=1.10.0->mistral_common[image]>=1.10.0->vllm) (0.26.0)
|
||||||
|
Collecting pycountry>=23 (from pydantic-extra-types[pycountry]>=2.10.5->mistral_common>=1.10.0->mistral_common[image]>=1.10.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/9c/42/7703bd45b62fecd44cd7d3495423097e2f7d28bc2e99e7c1af68892ab157/pycountry-26.2.16-py3-none-any.whl (8.0 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.0/8.0 MB 10.6 MB/s eta 0:00:00
|
||||||
|
Collecting python-dotenv>=0.21.0 (from pydantic-settings>=2.0.0->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0b/d7/1959b9648791274998a9c3526f6d0ec8fd2233e4d4acce81bbae76b44b2a/python_dotenv-1.2.2-py3-none-any.whl (22 kB)
|
||||||
|
Requirement already satisfied: cryptography>=3.4.0 in /root/miniconda3/lib/python3.12/site-packages (from pyjwt[crypto]>=2.10.1->mcp->vllm) (42.0.5)
|
||||||
|
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /root/miniconda3/lib/python3.12/site-packages (from sympy>=1.13.3->torch==2.10.0->vllm) (1.3.0)
|
||||||
|
Collecting httptools>=0.6.3 (from uvicorn[standard]>=0.12.0; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/84/a6/b3965e1e146ef5762870bbe76117876ceba51a201e18cc31f5703e454596/httptools-0.7.1-cp312-cp312-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl (517 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 517.7/517.7 kB 43.0 MB/s eta 0:00:00
|
||||||
|
Collecting uvloop>=0.15.1 (from uvicorn[standard]>=0.12.0; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/5f/6f/e62b4dfc7ad6518e7eff2516f680d02a0f6eb62c0c212e152ca708a0085e/uvloop-0.22.1-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (4.4 MB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.4/4.4 MB 12.6 MB/s eta 0:00:00
|
||||||
|
Collecting websockets>=10.4 (from uvicorn[standard]>=0.12.0; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/18/29/71729b4671f21e1eaa5d6573031ab810ad2936c8175f03f97f3ff164c802/websockets-16.0-cp312-cp312-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl (184 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 184.9/184.9 kB 22.0 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: cffi>=1.12 in /root/miniconda3/lib/python3.12/site-packages (from cryptography>=3.4.0->pyjwt[crypto]>=2.10.1->mcp->vllm) (1.16.0)
|
||||||
|
INFO: pip is looking at multiple versions of cuda-python to determine which version is compatible with other requirements. This could take a while.
|
||||||
|
Collecting cuda-python>=12.8 (from nvidia-cutlass-dsl-libs-base==4.4.2->nvidia-cutlass-dsl>=4.4.0.dev1->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/cd/08/b5e3b9822662d72d540d830531e3ab6a7cabbda3dd56175696aabccfeb76/cuda_python-13.1.1-py3-none-any.whl (8.0 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/3d/4d/876c2f87d34ccde0f11688f07e98a43cb3498cc115ee85fc7ae79711b7ae/cuda_python-13.1.0-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/31/5f/beaa12a11b051027eec0b041df01c6690db4f02e3b2e8fadd5a0eeb4df52/cuda_python-13.0.3-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/36/4d/d04772e5ba415aad4633796d636a3abbd8f779b438c3441d795e6bc9f172/cuda_python-13.0.2-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/02/02/078f4cba58349faad5597306ca54bf0bf129f8c713b261e1def59468a505/cuda_python-13.0.1-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/05/99/7df7b57a5eba85b25a76c9c247c88e79770b4902bce266dbf0fc58f21198/cuda_python-13.0.0-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/57/69/4a79126959ad6f1653504122ee1eb22d089dd6272d3fa37694dcdeb78ba5/cuda_python-12.9.6-py3-none-any.whl (7.6 kB)
|
||||||
|
INFO: pip is still looking at multiple versions of cuda-python to determine which version is compatible with other requirements. This could take a while.
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/0a/02/ce79a804a2d6ee7dc2d1637b75b7c3f01eb90a796915d4d3a1ac42e2d6e6/cuda_python-12.9.5-py3-none-any.whl (7.6 kB)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/af/f3/6b032a554019cfb3447e671798c1bd3e79b5f1af20d10253f56cea269ef2/cuda_python-12.9.4-py3-none-any.whl (7.6 kB)
|
||||||
|
Collecting rignore>=0.5.1 (from fastapi-cloud-cli>=0.1.1->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/85/e5/7f99bd0cc9818a91d0e8b9acc65b792e35750e3bdccd15a7ee75e64efca4/rignore-0.7.6-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (959 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 959.8/959.8 kB 9.2 MB/s eta 0:00:00
|
||||||
|
Collecting sentry-sdk>=2.20.0 (from fastapi-cloud-cli>=0.1.1->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/9a/66/20465097782d7e1e742d846407ea7262d338c6e876ddddad38ca8907b38f/sentry_sdk-2.55.0-py2.py3-none-any.whl (449 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 449.3/449.3 kB 16.4 MB/s eta 0:00:00
|
||||||
|
Collecting fastar>=0.8.0 (from fastapi-cloud-cli>=0.1.1->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm)
|
||||||
|
Downloading http://mirrors.aliyun.com/pypi/packages/41/df/d663214d35380b07a24a796c48d7d7d4dc3a28ec0756edbcb7e2a81dc572/fastar-0.9.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (819 kB)
|
||||||
|
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 819.0/819.0 kB 8.8 MB/s eta 0:00:00
|
||||||
|
Requirement already satisfied: rich>=13.7.1 in /root/miniconda3/lib/python3.12/site-packages (from rich-toolkit>=0.14.8->fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (14.3.3)
|
||||||
|
Requirement already satisfied: shellingham>=1.3.0 in /root/miniconda3/lib/python3.12/site-packages (from typer>=0.16.0->fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (1.5.4)
|
||||||
|
Requirement already satisfied: pycparser in /root/miniconda3/lib/python3.12/site-packages (from cffi>=1.12->cryptography>=3.4.0->pyjwt[crypto]>=2.10.1->mcp->vllm) (2.21)
|
||||||
|
Requirement already satisfied: markdown-it-py>=2.2.0 in /root/miniconda3/lib/python3.12/site-packages (from rich>=13.7.1->rich-toolkit>=0.14.8->fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (4.0.0)
|
||||||
|
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /root/miniconda3/lib/python3.12/site-packages (from rich>=13.7.1->rich-toolkit>=0.14.8->fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (2.19.2)
|
||||||
|
Requirement already satisfied: mdurl~=0.1 in /root/miniconda3/lib/python3.12/site-packages (from markdown-it-py>=2.2.0->rich>=13.7.1->rich-toolkit>=0.14.8->fastapi-cli>=0.0.8->fastapi-cli[standard]>=0.0.8; extra == "standard"->fastapi[standard]>=0.115.0->vllm) (0.1.2)
|
||||||
|
Installing collected packages: py-cpuinfo, nvidia-ml-py, zipp, websockets, uvloop, uvicorn, typing-inspection, triton, tabulate, setuptools, setproctitle, sentry-sdk, sentencepiece, safetensors, rignore, regex, python-multipart, python-dotenv, pyjwt, pydantic-core, pycountry, pybase64, protobuf, propcache, partial-json-parser, packaging, outlines_core, nvidia-nvshmem-cu12, nvidia-nccl-cu12, nvidia-cudnn-frontend, numpy, ninja, multidict, msgspec, loguru, llvmlite, llguidance, jmespath, jiter, interegular, ijson, httpx-sse, httptools, frozenlist, fastar, einops, docstring-parser, dnspython, diskcache, dill, cuda-pathfinder, cloudpickle, cbor2, cachetools, blake3, astor, apache-tvm-ffi, annotated-types, aiohappyeyeballs, yarl, watchfiles, tiktoken, starlette, pydantic, opentelemetry-proto, opencv-python-headless, numba, importlib-metadata, huggingface-hub, googleapis-common-protos, gguf, email-validator, depyf, cuda-bindings, aiosignal, torch, tokenizers, sse-starlette, rich-toolkit, pydantic-settings, pydantic-extra-types, prometheus-fastapi-instrumentator, opentelemetry-exporter-otlp-proto-common, opentelemetry-api, openai-harmony, openai, lm-format-enforcer, fastapi, cuda-python, anthropic, aiohttp, transformers, torchvision, torchaudio, torch-c-dlpack-ext, opentelemetry-semantic-conventions, nvidia-cutlass-dsl-libs-base, model-hosting-container-standards, mcp, fastapi-cloud-cli, fastapi-cli, xgrammar, opentelemetry-sdk, nvidia-cutlass-dsl, mistral_common, compressed-tensors, quack-kernels, opentelemetry-semantic-conventions-ai, opentelemetry-exporter-otlp-proto-http, opentelemetry-exporter-otlp-proto-grpc, flashinfer-python, opentelemetry-exporter-otlp, vllm
|
||||||
|
Attempting uninstall: triton
|
||||||
|
Found existing installation: triton 3.4.0
|
||||||
|
Uninstalling triton-3.4.0:
|
||||||
|
Successfully uninstalled triton-3.4.0
|
||||||
|
Attempting uninstall: setuptools
|
||||||
|
Found existing installation: setuptools 69.5.1
|
||||||
|
Uninstalling setuptools-69.5.1:
|
||||||
|
Successfully uninstalled setuptools-69.5.1
|
||||||
|
Attempting uninstall: protobuf
|
||||||
|
Found existing installation: protobuf 6.31.1
|
||||||
|
Uninstalling protobuf-6.31.1:
|
||||||
|
Successfully uninstalled protobuf-6.31.1
|
||||||
|
Attempting uninstall: packaging
|
||||||
|
Found existing installation: packaging 23.2
|
||||||
|
Uninstalling packaging-23.2:
|
||||||
|
Successfully uninstalled packaging-23.2
|
||||||
|
Attempting uninstall: nvidia-nccl-cu12
|
||||||
|
Found existing installation: nvidia-nccl-cu12 2.27.3
|
||||||
|
Uninstalling nvidia-nccl-cu12-2.27.3:
|
||||||
|
Successfully uninstalled nvidia-nccl-cu12-2.27.3
|
||||||
|
Attempting uninstall: numpy
|
||||||
|
Found existing installation: numpy 2.3.2
|
||||||
|
Uninstalling numpy-2.3.2:
|
||||||
|
Successfully uninstalled numpy-2.3.2
|
||||||
|
Attempting uninstall: huggingface-hub
|
||||||
|
Found existing installation: huggingface_hub 1.7.2
|
||||||
|
Uninstalling huggingface_hub-1.7.2:
|
||||||
|
Successfully uninstalled huggingface_hub-1.7.2
|
||||||
|
Attempting uninstall: torch
|
||||||
|
Found existing installation: torch 2.8.0+cu128
|
||||||
|
Uninstalling torch-2.8.0+cu128:
|
||||||
|
Successfully uninstalled torch-2.8.0+cu128
|
||||||
|
Attempting uninstall: torchvision
|
||||||
|
Found existing installation: torchvision 0.23.0+cu128
|
||||||
|
Uninstalling torchvision-0.23.0+cu128:
|
||||||
|
Successfully uninstalled torchvision-0.23.0+cu128
|
||||||
|
Successfully installed aiohappyeyeballs-2.6.1 aiohttp-3.13.3 aiosignal-1.4.0 annotated-types-0.7.0 anthropic-0.86.0 apache-tvm-ffi-0.1.9 astor-0.8.1 blake3-1.0.8 cachetools-7.0.5 cbor2-5.9.0 cloudpickle-3.1.2 compressed-tensors-0.13.0 cuda-bindings-12.9.4 cuda-pathfinder-1.4.4 cuda-python-12.9.4 depyf-0.20.0 dill-0.4.1 diskcache-5.6.3 dnspython-2.8.0 docstring-parser-0.17.0 einops-0.8.2 email-validator-2.3.0 fastapi-0.135.2 fastapi-cli-0.0.24 fastapi-cloud-cli-0.15.0 fastar-0.9.0 flashinfer-python-0.6.6 frozenlist-1.8.0 gguf-0.18.0 googleapis-common-protos-1.73.0 httptools-0.7.1 httpx-sse-0.4.3 huggingface-hub-0.36.2 ijson-3.5.0 importlib-metadata-8.7.1 interegular-0.3.3 jiter-0.13.0 jmespath-1.1.0 llguidance-1.3.0 llvmlite-0.44.0 lm-format-enforcer-0.11.3 loguru-0.7.3 mcp-1.26.0 mistral_common-1.10.0 model-hosting-container-standards-0.1.14 msgspec-0.20.0 multidict-6.7.1 ninja-1.13.0 numba-0.61.2 numpy-2.2.6 nvidia-cudnn-frontend-1.18.0 nvidia-cutlass-dsl-4.4.2 nvidia-cutlass-dsl-libs-base-4.4.2 nvidia-ml-py-13.595.45 nvidia-nccl-cu12-2.27.5 nvidia-nvshmem-cu12-3.4.5 openai-2.24.0 openai-harmony-0.0.8 opencv-python-headless-4.13.0.92 opentelemetry-api-1.40.0 opentelemetry-exporter-otlp-1.40.0 opentelemetry-exporter-otlp-proto-common-1.40.0 opentelemetry-exporter-otlp-proto-grpc-1.40.0 opentelemetry-exporter-otlp-proto-http-1.40.0 opentelemetry-proto-1.40.0 opentelemetry-sdk-1.40.0 opentelemetry-semantic-conventions-0.61b0 opentelemetry-semantic-conventions-ai-0.5.0 outlines_core-0.2.11 packaging-26.0 partial-json-parser-0.2.1.1.post7 prometheus-fastapi-instrumentator-7.1.0 propcache-0.4.1 protobuf-6.33.6 py-cpuinfo-9.0.0 pybase64-1.4.3 pycountry-26.2.16 pydantic-2.12.5 pydantic-core-2.41.5 pydantic-extra-types-2.11.1 pydantic-settings-2.13.1 pyjwt-2.12.1 python-dotenv-1.2.2 python-multipart-0.0.22 quack-kernels-0.3.5 regex-2026.2.28 rich-toolkit-0.19.7 rignore-0.7.6 safetensors-0.7.0 sentencepiece-0.2.1 sentry-sdk-2.55.0 setproctitle-1.3.7 setuptools-80.10.2 sse-starlette-3.3.3 starlette-0.52.1 tabulate-0.10.0 tiktoken-0.12.0 tokenizers-0.22.2 torch-2.10.0 torch-c-dlpack-ext-0.1.5 torchaudio-2.10.0 torchvision-0.25.0 transformers-4.57.6 triton-3.6.0 typing-inspection-0.4.2 uvicorn-0.42.0 uvloop-0.22.1 vllm-0.18.0 watchfiles-1.1.1 websockets-16.0 xgrammar-0.1.32 yarl-1.23.0 zipp-3.23.0
|
||||||
|
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
|
||||||
|
root@autodl-container-c6d54aa471-4479d4d0:~/autodl-tmp#
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
## 一、你最终安装的核心东西是什么?
|
||||||
|
|
||||||
|
你执行的是:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
最终成功安装了:
|
||||||
|
|
||||||
|
- **vllm 0.18.0**
|
||||||
|
|
||||||
|
它不是单独一个包,而是顺带安装了一大堆依赖,主要可以分成几类:
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 二、最核心的大件
|
||||||
|
|
||||||
|
这几个是体积最大、最关键的:
|
||||||
|
|
||||||
|
### 1. vLLM 本体
|
||||||
|
|
||||||
|
- **vllm-0.18.0**
|
||||||
|
|
||||||
|
这是高性能大模型推理框架本身,用来部署/推理 LLM。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 2. PyTorch 整套
|
||||||
|
|
||||||
|
你安装/替换了:
|
||||||
|
|
||||||
|
- **torch 2.10.0**
|
||||||
|
- **torchvision 0.25.0**
|
||||||
|
- **torchaudio 2.10.0**
|
||||||
|
- **triton 3.6.0**
|
||||||
|
|
||||||
|
这说明 vLLM 把你原来环境里的 PyTorch 升级/替换成了它需要的版本。
|
||||||
|
|
||||||
|
日志里明确显示它卸载了原有版本:
|
||||||
|
|
||||||
|
- 卸载了 **torch 2.8.0+cu128**
|
||||||
|
- 卸载了 **torchvision 0.23.0+cu128**
|
||||||
|
- 卸载了 **triton 3.4.0**
|
||||||
|
|
||||||
|
也就是说,你现在的推理底座已经变成:
|
||||||
|
|
||||||
|
- **PyTorch 2.10.0**
|
||||||
|
- CUDA 12 相关依赖配套版本
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 3. CUDA / NVIDIA 相关高性能组件
|
||||||
|
|
||||||
|
新装或调整了这些:
|
||||||
|
|
||||||
|
- **nvidia-nccl-cu12 2.27.5**
|
||||||
|
- **nvidia-nvshmem-cu12 3.4.5**
|
||||||
|
- **nvidia-cudnn-frontend 1.18.0**
|
||||||
|
- **cuda-bindings 12.9.4**
|
||||||
|
- **cuda-python 12.9.4**
|
||||||
|
- **cuda-pathfinder 1.4.4**
|
||||||
|
- **nvidia-cutlass-dsl 4.4.2**
|
||||||
|
- **nvidia-cutlass-dsl-libs-base 4.4.2**
|
||||||
|
- **nvidia-ml-py 13.595.45**
|
||||||
|
|
||||||
|
这些主要作用:
|
||||||
|
|
||||||
|
- GPU 通信
|
||||||
|
- CUDA API 绑定
|
||||||
|
- 高性能 kernel
|
||||||
|
- 多卡推理支持
|
||||||
|
- NVIDIA 底层算子优化
|
||||||
|
|
||||||
|
其中:
|
||||||
|
|
||||||
|
- **NCCL**:多卡通信关键组件
|
||||||
|
- **NVSHMEM**:高性能 GPU 间共享内存通信
|
||||||
|
- **CUTLASS DSL**:NVIDIA 高性能 GEMM/算子支持
|
||||||
|
- **CUDA Python / Bindings**:让 Python 能直接调用 CUDA 能力
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 4. vLLM 专用高性能推理加速组件
|
||||||
|
|
||||||
|
这几个也很关键:
|
||||||
|
|
||||||
|
- **flashinfer-python 0.6.6**
|
||||||
|
- **quack-kernels 0.3.5**
|
||||||
|
- **torch-c-dlpack-ext 0.1.5**
|
||||||
|
- **compressed-tensors 0.13.0**
|
||||||
|
- **depyf 0.20.0**
|
||||||
|
- **apache-tvm-ffi 0.1.9**
|
||||||
|
|
||||||
|
作用大概是:
|
||||||
|
|
||||||
|
- 加速 attention / decoding
|
||||||
|
- 优化张量操作
|
||||||
|
- 支持压缩权重
|
||||||
|
- 支持更底层高性能 kernel
|
||||||
|
- 一些编译/调度/FFI 能力
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 三、模型生态相关依赖
|
||||||
|
|
||||||
|
这些是为了支持 HuggingFace 模型、tokenizer、权重格式等:
|
||||||
|
|
||||||
|
- **transformers 4.57.6**
|
||||||
|
- **tokenizers 0.22.2**
|
||||||
|
- **huggingface-hub 0.36.2**
|
||||||
|
- **safetensors 0.7.0**
|
||||||
|
- **sentencepiece 0.2.1**
|
||||||
|
- **tiktoken 0.12.0**
|
||||||
|
- **gguf 0.18.0**
|
||||||
|
- **mistral_common 1.10.0**
|
||||||
|
- **openai-harmony 0.0.8**
|
||||||
|
|
||||||
|
### 它们分别干嘛:
|
||||||
|
|
||||||
|
- **transformers**:加载 HuggingFace 模型
|
||||||
|
- **tokenizers / sentencepiece / tiktoken**:分词器
|
||||||
|
- **huggingface-hub**:从 HF 下载模型
|
||||||
|
- **safetensors**:加载 safetensors 权重
|
||||||
|
- **gguf**:支持 GGUF 格式模型
|
||||||
|
- **mistral_common**:Mistral 模型相关支持
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 四、API 服务相关依赖
|
||||||
|
|
||||||
|
vLLM 很常见的用法是启动 OpenAI 兼容服务,所以安装了 Web/API 框架:
|
||||||
|
|
||||||
|
- **fastapi 0.135.2**
|
||||||
|
- **starlette 0.52.1**
|
||||||
|
- **uvicorn 0.42.0**
|
||||||
|
- **uvloop 0.22.1**
|
||||||
|
- **httptools 0.7.1**
|
||||||
|
- **websockets 16.0**
|
||||||
|
- **watchfiles 1.1.1**
|
||||||
|
- **python-multipart 0.0.22**
|
||||||
|
- **email-validator 2.3.0**
|
||||||
|
- **fastapi-cli 0.0.24**
|
||||||
|
- **fastapi-cloud-cli 0.15.0**
|
||||||
|
- **prometheus-fastapi-instrumentator 7.1.0**
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 启动 HTTP 服务
|
||||||
|
- 提供 OpenAI 风格 API
|
||||||
|
- 处理 websocket / multipart
|
||||||
|
- 自动监控接口指标
|
||||||
|
- 热更新/文件监控
|
||||||
|
|
||||||
|
也就是说,你现在环境已经具备了直接跑:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
vllm serve ...
|
||||||
|
```
|
||||||
|
|
||||||
|
或者类似 OpenAI API 服务的能力。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 五、OpenAI / Anthropic / MCP 相关客户端
|
||||||
|
|
||||||
|
你还安装了:
|
||||||
|
|
||||||
|
- **openai 2.24.0**
|
||||||
|
- **anthropic 0.86.0**
|
||||||
|
- **mcp 1.26.0**
|
||||||
|
- **httpx-sse 0.4.3**
|
||||||
|
- **sse-starlette 3.3.3**
|
||||||
|
- **pyjwt 2.12.1**
|
||||||
|
|
||||||
|
这部分主要是为了:
|
||||||
|
|
||||||
|
- 兼容 OpenAI 接口风格
|
||||||
|
- 兼容 Anthropic 风格
|
||||||
|
- 支持 MCP(Model Context Protocol)相关功能
|
||||||
|
- 支持 SSE 流式输出
|
||||||
|
- 认证/鉴权
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 六、约束解码 / 结构化输出相关
|
||||||
|
|
||||||
|
这些是 vLLM 比较新的一类能力,支持 JSON schema、语法约束解码等:
|
||||||
|
|
||||||
|
- **lm-format-enforcer 0.11.3**
|
||||||
|
- **llguidance 1.3.0**
|
||||||
|
- **outlines_core 0.2.11**
|
||||||
|
- **xgrammar 0.1.32**
|
||||||
|
- **partial-json-parser 0.2.1.1.post7**
|
||||||
|
- **interegular 0.3.3**
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 强制模型输出符合 JSON/语法规则
|
||||||
|
- 结构化生成
|
||||||
|
- grammar-guided decoding
|
||||||
|
- 部分 JSON 流式解析
|
||||||
|
|
||||||
|
如果你要做“模型输出必须是 JSON”这种功能,这些包就是相关支持。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 七、监控 / 可观测性相关
|
||||||
|
|
||||||
|
安装了 OpenTelemetry 一整套:
|
||||||
|
|
||||||
|
- **opentelemetry-api 1.40.0**
|
||||||
|
- **opentelemetry-sdk 1.40.0**
|
||||||
|
- **opentelemetry-exporter-otlp 1.40.0**
|
||||||
|
- **opentelemetry-exporter-otlp-proto-common 1.40.0**
|
||||||
|
- **opentelemetry-exporter-otlp-proto-grpc 1.40.0**
|
||||||
|
- **opentelemetry-exporter-otlp-proto-http 1.40.0**
|
||||||
|
- **opentelemetry-proto 1.40.0**
|
||||||
|
- **opentelemetry-semantic-conventions 0.61b0**
|
||||||
|
- **opentelemetry-semantic-conventions-ai 0.5.0**
|
||||||
|
- **googleapis-common-protos 1.73.0**
|
||||||
|
- **protobuf 6.33.6**
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 打点
|
||||||
|
- tracing
|
||||||
|
- metrics
|
||||||
|
- 将监控数据发给 OTLP 后端
|
||||||
|
|
||||||
|
如果你部署线上服务,这部分是有用的。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 八、数值计算 / 编译优化相关
|
||||||
|
|
||||||
|
- **numba 0.61.2**
|
||||||
|
- **llvmlite 0.44.0**
|
||||||
|
- **numpy 2.2.6**
|
||||||
|
- **einops 0.8.2**
|
||||||
|
- **cloudpickle 3.1.2**
|
||||||
|
- **msgspec 0.20.0**
|
||||||
|
- **ijson 3.5.0**
|
||||||
|
- **cbor2 5.9.0**
|
||||||
|
- **blake3 1.0.8**
|
||||||
|
|
||||||
|
这些属于:
|
||||||
|
|
||||||
|
- 数值计算
|
||||||
|
- JIT/LLVM 编译支持
|
||||||
|
- 数据序列化/反序列化
|
||||||
|
- 哈希
|
||||||
|
- JSON 流式解析
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 九、图像/多模态相关
|
||||||
|
|
||||||
|
你还装了:
|
||||||
|
|
||||||
|
- **opencv-python-headless 4.13.0.92**
|
||||||
|
- **pillow** 已经存在
|
||||||
|
- **torchvision**
|
||||||
|
- **mistral_common[image]** 相关依赖
|
||||||
|
|
||||||
|
这说明 vLLM 这版不只是纯文本,也带了一些多模态/图像处理支持。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 十、一些工具类依赖
|
||||||
|
|
||||||
|
比如:
|
||||||
|
|
||||||
|
- **regex**
|
||||||
|
- **cachetools**
|
||||||
|
- **diskcache**
|
||||||
|
- **py-cpuinfo**
|
||||||
|
- **ninja**
|
||||||
|
- **setproctitle**
|
||||||
|
- **pybase64**
|
||||||
|
- **loguru**
|
||||||
|
- **tabulate**
|
||||||
|
- **packaging 26.0**
|
||||||
|
- **setuptools 80.10.2**
|
||||||
|
- **importlib-metadata 8.7.1**
|
||||||
|
- **zipp 3.23.0**
|
||||||
|
- **dnspython 2.8.0**
|
||||||
|
- **python-dotenv 1.2.2**
|
||||||
|
- **docstring-parser 0.17.0**
|
||||||
|
- **jmespath 1.1.0**
|
||||||
|
- **rignore 0.7.6**
|
||||||
|
- **sentry-sdk 2.55.0**
|
||||||
|
- **fastar 0.9.0**
|
||||||
|
|
||||||
|
这些一般是:
|
||||||
|
|
||||||
|
- 构建工具
|
||||||
|
- 日志
|
||||||
|
- 配置管理
|
||||||
|
- 缓存
|
||||||
|
- 监控
|
||||||
|
- 辅助解析
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 十一、这次安装替换了你环境里的哪些已有包?
|
||||||
|
|
||||||
|
从日志里能明确看到,以下包被替换了:
|
||||||
|
|
||||||
|
### 被卸载并重装/降级/升级的
|
||||||
|
|
||||||
|
- **triton**:3.4.0 → 3.6.0
|
||||||
|
- **setuptools**:69.5.1 → 80.10.2
|
||||||
|
- **protobuf**:6.31.1 → 6.33.6
|
||||||
|
- **packaging**:23.2 → 26.0
|
||||||
|
- **nvidia-nccl-cu12**:2.27.3 → 2.27.5
|
||||||
|
- **numpy**:2.3.2 → 2.2.6
|
||||||
|
- **huggingface-hub**:1.7.2 → 0.36.2
|
||||||
|
- **torch**:2.8.0+cu128 → 2.10.0
|
||||||
|
- **torchvision**:0.23.0+cu128 → 0.25.0
|
||||||
|
|
||||||
|
### 这里要特别注意两点:
|
||||||
|
|
||||||
|
#### 1)huggingface-hub 被“降版本”了
|
||||||
|
|
||||||
|
从:
|
||||||
|
|
||||||
|
- 1.7.2 → 0.36.2
|
||||||
|
|
||||||
|
这通常是因为 `transformers/tokenizers/vllm` 当前依赖链要求 `<1.0` 风格版本。
|
||||||
|
|
||||||
|
#### 2)numpy 被换成了 2.2.6
|
||||||
|
|
||||||
|
原来是 2.3.2,现在是 2.2.6。
|
||||||
|
|
||||||
|
这是依赖兼容性导致的,不算异常。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 十二、按功能给你一个简版总结
|
||||||
|
|
||||||
|
你这次安装,本质上装了:
|
||||||
|
|
||||||
|
### 1. vLLM 主程序
|
||||||
|
|
||||||
|
- vllm
|
||||||
|
|
||||||
|
### 2. 大模型推理底座
|
||||||
|
|
||||||
|
- torch / torchvision / torchaudio / triton
|
||||||
|
|
||||||
|
### 3. GPU 高性能依赖
|
||||||
|
|
||||||
|
- NCCL / NVSHMEM / CUDA bindings / CUTLASS / flashinfer / quack kernels
|
||||||
|
|
||||||
|
### 4. HuggingFace 模型生态
|
||||||
|
|
||||||
|
- transformers / tokenizers / huggingface-hub / sentencepiece / safetensors / tiktoken
|
||||||
|
|
||||||
|
### 5. Web 服务框架
|
||||||
|
|
||||||
|
- fastapi / uvicorn / starlette / websockets
|
||||||
|
|
||||||
|
### 6. 结构化输出与语法约束
|
||||||
|
|
||||||
|
- lm-format-enforcer / llguidance / xgrammar / outlines_core
|
||||||
|
|
||||||
|
### 7. 监控与可观测性
|
||||||
|
|
||||||
|
- prometheus / opentelemetry 全家桶
|
||||||
|
|
||||||
|
### 8. 多模态支持
|
||||||
|
|
||||||
|
- opencv-python-headless / torchvision / mistral_common
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 十三、占空间最大的几个包
|
||||||
|
|
||||||
|
从日志看,比较大的有:
|
||||||
|
|
||||||
|
- **torch-2.10.0**:915.6 MB
|
||||||
|
- **vllm-0.18.0**:433.2 MB
|
||||||
|
- **nvidia-nccl-cu12**:322.3 MB
|
||||||
|
- **triton-3.6.0**:188.3 MB
|
||||||
|
- **nvidia-nvshmem-cu12**:139.1 MB
|
||||||
|
- **nvidia-cutlass-dsl-libs-base**:74.4 MB
|
||||||
|
- **opencv-python-headless**:60.4 MB
|
||||||
|
- **llvmlite**:42.4 MB
|
||||||
|
- **xgrammar**:37.7 MB
|
||||||
|
|
||||||
|
所以这次安装是很重的一次安装,不是一个轻量包。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 十四、最终结论
|
||||||
|
|
||||||
|
一句话总结:
|
||||||
|
|
||||||
|
**你安装的不只是 vLLM 本身,而是一整套“LLM 推理服务运行环境”**,包括:
|
||||||
|
|
||||||
|
- vLLM 本体
|
||||||
|
- PyTorch 2.10 + Triton
|
||||||
|
- CUDA/NVIDIA 高性能推理组件
|
||||||
|
- HuggingFace 模型加载生态
|
||||||
|
- FastAPI/uvicorn 服务框架
|
||||||
|
- OpenAI 兼容 API 支持
|
||||||
|
- 结构化输出/语法约束生成
|
||||||
|
- 监控和可观测性组件
|
||||||
|
- 一部分多模态支持
|
||||||
|
|
||||||
|
同时它还**替换了你环境中原有的 torch、torchvision、triton、numpy、protobuf、huggingface-hub 等包**。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
如果你愿意,我还可以进一步帮你做两件事里的任意一种:
|
||||||
|
|
||||||
|
1. **把这份日志整理成“安装包清单表格”**(包名 / 版本 / 作用)
|
||||||
|
2. **帮你判断这个 vllm 环境是否和你当前 CUDA、显卡、驱动兼容**
|
||||||
@@ -0,0 +1,730 @@
|
|||||||
|
```
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [api_server.py:580] Starting vLLM server on http://0.0.0.0:6006
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:37] Available routes are:
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /openapi.json, Methods: HEAD, GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /docs, Methods: HEAD, GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /docs/oauth2-redirect, Methods: HEAD, GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /redoc, Methods: HEAD, GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /tokenize, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /detokenize, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /load, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /version, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /health, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /metrics, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/models, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /ping, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /ping, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /invocations, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/chat/completions, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/responses, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/responses/{response_id}, Methods: GET
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/responses/{response_id}/cancel, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/completions, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/messages, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/messages/count_tokens, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /inference/v1/generate, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /scale_elastic_ep, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /is_scaling_elastic_ep, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/chat/completions/render, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO 03-24 13:28:31 [launcher.py:46] Route: /v1/completions/render, Methods: POST
|
||||||
|
(APIServer pid=17207) INFO: Started server process [17207]
|
||||||
|
(APIServer pid=17207) INFO: Waiting for application startup.
|
||||||
|
(APIServer pid=17207) INFO: Application startup complete.
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# 一、最前面的基础信息
|
||||||
|
|
||||||
|
## 1)版本和模型路径
|
||||||
|
|
||||||
|
```bash
|
||||||
|
version 0.18.0
|
||||||
|
model /root/autodl-tmp/DeepSeek-R1-32B
|
||||||
|
```
|
||||||
|
|
||||||
|
表示:
|
||||||
|
|
||||||
|
- 当前 vLLM 版本:`0.18.0`
|
||||||
|
- 加载的模型目录:`/root/autodl-tmp/DeepSeek-R1-32B`
|
||||||
|
|
||||||
|
这是最基础的确认信息。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 2)非默认启动参数
|
||||||
|
|
||||||
|
```bash
|
||||||
|
non-default args: {
|
||||||
|
'port': 6006,
|
||||||
|
'model': '/root/autodl-tmp/DeepSeek-R1-32B',
|
||||||
|
'max_model_len': 8192,
|
||||||
|
'served_model_name': ['deepseek-r1'],
|
||||||
|
'gpu_memory_utilization': 0.95
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这里列的是你手动指定、不同于默认值的参数。
|
||||||
|
|
||||||
|
你的关键参数含义:
|
||||||
|
|
||||||
|
- `port: 6006`
|
||||||
|
服务监听端口是 6006
|
||||||
|
|
||||||
|
- `model: /root/autodl-tmp/DeepSeek-R1-32B`
|
||||||
|
模型目录
|
||||||
|
|
||||||
|
- `max_model_len: 8192`
|
||||||
|
最大上下文长度 8192 token
|
||||||
|
|
||||||
|
- `served_model_name: deepseek-r1`
|
||||||
|
API 层暴露给客户端的模型名
|
||||||
|
|
||||||
|
- `gpu_memory_utilization: 0.95`
|
||||||
|
vLLM 最多使用 95% GPU 显存来做模型和缓存分配
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 二、模型识别与调度信息
|
||||||
|
|
||||||
|
## 3)模型架构识别
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Resolved architecture: Qwen2ForCausalLM
|
||||||
|
```
|
||||||
|
|
||||||
|
说明 vLLM 识别出这个模型底层架构是:
|
||||||
|
|
||||||
|
- `Qwen2ForCausalLM`
|
||||||
|
|
||||||
|
虽然你目录叫 DeepSeek-R1-32B,但很多 DeepSeek 模型底层是兼容 Qwen 架构的,所以这是正常的。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 4)最大长度设置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Using max model len 8192
|
||||||
|
```
|
||||||
|
|
||||||
|
表示最终采用的最大序列长度是 8192。
|
||||||
|
|
||||||
|
这个值会直接影响:
|
||||||
|
|
||||||
|
- KV Cache 占用
|
||||||
|
- 最大并发
|
||||||
|
- 显存使用
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 5)Chunked Prefill
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Chunked prefill is enabled with max_num_batched_tokens=8192.
|
||||||
|
```
|
||||||
|
|
||||||
|
说明启用了 **分块预填充(chunked prefill)**。
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 输入 prompt 很长时,不是一次性全部 prefill,而是按块处理
|
||||||
|
- 能改善吞吐和显存使用
|
||||||
|
- 对长上下文模型很有帮助
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 6)异步调度
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Asynchronous scheduling is enabled.
|
||||||
|
```
|
||||||
|
|
||||||
|
表示启用了 **异步调度器**。
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 更好地调度多个请求
|
||||||
|
- 通常提升吞吐
|
||||||
|
- 对服务化部署更友好
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 三、Engine 初始化配置
|
||||||
|
|
||||||
|
这段很重要:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Initializing a V1 LLM engine (v0.18.0) with config: ...
|
||||||
|
```
|
||||||
|
|
||||||
|
这是整个推理引擎的详细配置总表。里面关键信息包括:
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 7)dtype
|
||||||
|
|
||||||
|
```bash
|
||||||
|
dtype=torch.bfloat16
|
||||||
|
```
|
||||||
|
|
||||||
|
模型以 `bfloat16` 精度运行。
|
||||||
|
|
||||||
|
说明:
|
||||||
|
|
||||||
|
- 显存比 fp32 小很多
|
||||||
|
- 通常速度更快
|
||||||
|
- 需要 GPU 支持 bf16
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 8)并行配置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
tensor_parallel_size=1
|
||||||
|
pipeline_parallel_size=1
|
||||||
|
data_parallel_size=1
|
||||||
|
```
|
||||||
|
|
||||||
|
表示当前都是单卡/单副本:
|
||||||
|
|
||||||
|
- 张量并行 TP = 1
|
||||||
|
- 流水线并行 PP = 1
|
||||||
|
- 数据并行 DP = 1
|
||||||
|
|
||||||
|
也就是:**你现在实际上是单卡部署**。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 9)前缀缓存
|
||||||
|
|
||||||
|
```bash
|
||||||
|
enable_prefix_caching=True
|
||||||
|
```
|
||||||
|
|
||||||
|
表示启用了 **prefix caching(前缀缓存)**。
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 如果多个请求共享相同前缀 prompt
|
||||||
|
- 可以复用前缀计算结果
|
||||||
|
- 节省时间,提高吞吐
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 10)编译配置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
compilation_config=...
|
||||||
|
backend='inductor'
|
||||||
|
cudagraph_mode=FULL_AND_PIECEWISE
|
||||||
|
```
|
||||||
|
|
||||||
|
说明 vLLM 启用了编译优化和 CUDA Graph:
|
||||||
|
|
||||||
|
- `torch.compile`
|
||||||
|
- `inductor`
|
||||||
|
- CUDA Graph
|
||||||
|
|
||||||
|
这会提高推理性能,但启动时会多花一些时间做 warmup 和 graph capture。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 四、分布式与 rank 信息
|
||||||
|
|
||||||
|
## 11)world size / rank
|
||||||
|
|
||||||
|
```bash
|
||||||
|
world_size=1 rank=0 local_rank=0 ... backend=nccl
|
||||||
|
```
|
||||||
|
|
||||||
|
说明:
|
||||||
|
|
||||||
|
- 总进程数:1
|
||||||
|
- 当前 rank:0
|
||||||
|
- 本地 rank:0
|
||||||
|
- 通信后端:NCCL
|
||||||
|
|
||||||
|
虽然你只有单卡,但 vLLM 内部还是走统一的分布式初始化逻辑,这是正常的。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 12)并行角色分配
|
||||||
|
|
||||||
|
```bash
|
||||||
|
rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0
|
||||||
|
```
|
||||||
|
|
||||||
|
表示当前唯一这个进程兼任所有角色。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 五、模型加载阶段
|
||||||
|
|
||||||
|
## 13)开始加载模型
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Starting to load model /root/autodl-tmp/DeepSeek-R1-32B...
|
||||||
|
```
|
||||||
|
|
||||||
|
开始读取模型权重。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 14)Attention 后端
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Using FLASH_ATTN attention backend ...
|
||||||
|
Using FlashAttention version 2
|
||||||
|
```
|
||||||
|
|
||||||
|
说明 vLLM 最终选用了:
|
||||||
|
|
||||||
|
- `FLASH_ATTN`
|
||||||
|
- 版本 `FlashAttention v2`
|
||||||
|
|
||||||
|
这是高性能 attention 实现,通常是比较理想的情况。
|
||||||
|
|
||||||
|
候选后端里还有:
|
||||||
|
|
||||||
|
- FLASHINFER
|
||||||
|
- TRITON_ATTN
|
||||||
|
- FLEX_ATTENTION
|
||||||
|
|
||||||
|
但最终选择了 FlashAttention。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 15)checkpoint shard 加载进度
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Loading safetensors checkpoint shards: ...
|
||||||
|
```
|
||||||
|
|
||||||
|
表示模型权重是分片存储的,一共 `8` 个 shard。
|
||||||
|
|
||||||
|
日志里看到:
|
||||||
|
|
||||||
|
- 0/8
|
||||||
|
- 1/8
|
||||||
|
- …
|
||||||
|
- 8/8
|
||||||
|
|
||||||
|
说明模型权重成功全部加载完成。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 16)权重加载耗时
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Loading weights took 13.38 seconds
|
||||||
|
```
|
||||||
|
|
||||||
|
纯粹“读权重文件并装入”的时间是 13.38 秒。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 17)模型加载显存占用
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Model loading took 61.06 GiB memory and 14.101032 seconds
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个非常关键的信息:
|
||||||
|
|
||||||
|
- 模型加载后占用了 `61.06 GiB` 显存
|
||||||
|
- 总耗时约 `14.1 秒`
|
||||||
|
|
||||||
|
这能帮助你判断:
|
||||||
|
|
||||||
|
- 模型本体有多大
|
||||||
|
- 剩余显存还能留多少给 KV Cache 和 CUDA Graph
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 六、编译和缓存信息
|
||||||
|
|
||||||
|
## 18)torch.compile 缓存目录
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Using cache directory: /root/.cache/vllm/torch_compile_cache/...
|
||||||
|
```
|
||||||
|
|
||||||
|
说明 vLLM 使用这个目录缓存 `torch.compile` 的编译结果。
|
||||||
|
|
||||||
|
好处:
|
||||||
|
|
||||||
|
- 下次重启如果配置没变,可能直接复用缓存
|
||||||
|
- 启动速度更快
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 19)编译耗时
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Dynamo bytecode transform time: 4.52 s
|
||||||
|
torch.compile took 7.13 s in total
|
||||||
|
```
|
||||||
|
|
||||||
|
表示:
|
||||||
|
|
||||||
|
- Dynamo 变换用了 4.52 秒
|
||||||
|
- 整体 compile 用了 7.13 秒
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 20)直接从缓存加载编译图
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Directly load the compiled graph(s) ... from the cache
|
||||||
|
Directly load AOT compilation from path ...
|
||||||
|
```
|
||||||
|
|
||||||
|
说明你这次并不是全量重新编译,而是 **命中了历史缓存**。
|
||||||
|
|
||||||
|
所以启动会快很多。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 七、warmup 和 profiling
|
||||||
|
|
||||||
|
## 21)初始 profiling / warmup
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Initial profiling/warmup run took 2.69 s
|
||||||
|
```
|
||||||
|
|
||||||
|
表示模型做了一次预热运行:
|
||||||
|
|
||||||
|
- 激活算子
|
||||||
|
- 建立执行图
|
||||||
|
- 为后面正式推理做准备
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 八、KV Cache 相关信息
|
||||||
|
|
||||||
|
这部分是服务性能、并发能力最关键的。
|
||||||
|
|
||||||
|
## 22)KV cache block override
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Overriding num_gpu_blocks=0 with num_gpu_blocks_override=512
|
||||||
|
```
|
||||||
|
|
||||||
|
说明最终 GPU KV Cache block 数被设为 `512`。
|
||||||
|
|
||||||
|
这个值决定了可缓存多少 token。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 23)CUDA graph 显存估计
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Estimated CUDA graph memory: 0.93 GiB total
|
||||||
|
```
|
||||||
|
|
||||||
|
表示 CUDA graph 本身大概占用 `0.93 GiB` 显存。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 24)可用于 KV cache 的显存
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Available KV cache memory: 11.89 GiB
|
||||||
|
```
|
||||||
|
|
||||||
|
这是很关键的一行:
|
||||||
|
|
||||||
|
- 模型权重 + 编译 + graph 占完之后
|
||||||
|
- 剩下给 KV Cache 的显存是 `11.89 GiB`
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 25)GPU KV cache size
|
||||||
|
|
||||||
|
```bash
|
||||||
|
GPU KV cache size: 48,704 tokens
|
||||||
|
```
|
||||||
|
|
||||||
|
表示 GPU 上最多可缓存约:
|
||||||
|
|
||||||
|
- `48,704 token`
|
||||||
|
|
||||||
|
这是总 token 容量,不是单请求。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 26)最大并发估算
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Maximum concurrency for 8,192 tokens per request: 5.95x
|
||||||
|
```
|
||||||
|
|
||||||
|
意思是:
|
||||||
|
|
||||||
|
- 如果每个请求都占满 `8192 token`
|
||||||
|
- 理论上最多支持接近 `5.95` 个这样的请求同时驻留
|
||||||
|
|
||||||
|
也就是大约 **5~6 个满长请求并发**
|
||||||
|
|
||||||
|
这是一个“理论上限估计”,实际情况还会受生成长度、调度、碎片等影响。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 九、CUDA Graph 捕获
|
||||||
|
|
||||||
|
## 27)捕获过程
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): ...
|
||||||
|
Capturing CUDA graphs (decode, FULL): ...
|
||||||
|
```
|
||||||
|
|
||||||
|
表示 vLLM 正在为不同 batch size / 场景捕获 CUDA Graph。
|
||||||
|
|
||||||
|
作用:
|
||||||
|
|
||||||
|
- 降低 kernel launch 开销
|
||||||
|
- 提升推理速度
|
||||||
|
- 尤其对稳定 batch 的在线推理很有用
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 28)捕获结果
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Graph capturing finished in 13 secs, took 0.93 GiB
|
||||||
|
CUDA graph pool memory: 0.93 GiB (actual), 0.93 GiB (estimated)
|
||||||
|
```
|
||||||
|
|
||||||
|
说明:
|
||||||
|
|
||||||
|
- Graph capture 总共耗时 13 秒
|
||||||
|
- 占显存 0.93 GiB
|
||||||
|
- 实测和预估几乎一致
|
||||||
|
|
||||||
|
这是正常且比较理想的结果。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 29)Engine 初始化总耗时
|
||||||
|
|
||||||
|
```bash
|
||||||
|
init engine (profile, create kv cache, warmup model) took 25.79 seconds
|
||||||
|
```
|
||||||
|
|
||||||
|
表示引擎最终初始化总耗时约:
|
||||||
|
|
||||||
|
- `25.79 秒`
|
||||||
|
|
||||||
|
包括:
|
||||||
|
|
||||||
|
- profiling
|
||||||
|
- 创建 KV cache
|
||||||
|
- warmup
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十、API 服务层信息
|
||||||
|
|
||||||
|
## 30)支持的任务
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Supported tasks: ['generate']
|
||||||
|
```
|
||||||
|
|
||||||
|
说明当前模型/服务支持的任务是:
|
||||||
|
|
||||||
|
- `generate`
|
||||||
|
|
||||||
|
也就是文本生成类任务。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 31)generation_config 覆盖提醒
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Default vLLM sampling parameters have been overridden by the model's `generation_config.json`: {'temperature': 0.6, 'top_p': 0.95}
|
||||||
|
```
|
||||||
|
|
||||||
|
表示模型目录里的 `generation_config.json` 覆盖了 vLLM 默认采样参数。
|
||||||
|
|
||||||
|
当前默认采样变成:
|
||||||
|
|
||||||
|
- `temperature = 0.6`
|
||||||
|
- `top_p = 0.95`
|
||||||
|
|
||||||
|
如果你不想让模型自带配置生效,可以加:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
--generation-config vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 32)chat template 格式检测
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Detected the chat template content format to be 'string'
|
||||||
|
```
|
||||||
|
|
||||||
|
说明 vLLM 检测到聊天模板内容格式是 `string`。
|
||||||
|
|
||||||
|
一般不用管,除非你自定义 chat template。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 33)服务启动地址
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Starting vLLM server on http://0.0.0.0:6006
|
||||||
|
```
|
||||||
|
|
||||||
|
表示:
|
||||||
|
|
||||||
|
- 监听所有网卡:`0.0.0.0`
|
||||||
|
- 端口:`6006`
|
||||||
|
|
||||||
|
如果你本机访问,就是:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
http://127.0.0.1:6006
|
||||||
|
```
|
||||||
|
|
||||||
|
如果外部访问,要换成宿主机 IP。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十一、可用接口列表
|
||||||
|
|
||||||
|
日志中列出了所有路由。最常用的是:
|
||||||
|
|
||||||
|
## OpenAI 兼容接口
|
||||||
|
|
||||||
|
- `/v1/chat/completions`
|
||||||
|
- `/v1/completions`
|
||||||
|
- `/v1/models`
|
||||||
|
|
||||||
|
## 其他接口
|
||||||
|
|
||||||
|
- `/health`:健康检查
|
||||||
|
- `/metrics`:监控指标
|
||||||
|
- `/version`:版本信息
|
||||||
|
- `/tokenize`:分词
|
||||||
|
- `/detokenize`:反分词
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十二、Uvicorn/FastAPI 启动完成
|
||||||
|
|
||||||
|
最后几行:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Started server process [70536]
|
||||||
|
Waiting for application startup.
|
||||||
|
Application startup complete.
|
||||||
|
```
|
||||||
|
|
||||||
|
这表示:
|
||||||
|
|
||||||
|
- API server 进程已经启动
|
||||||
|
- 应用初始化完成
|
||||||
|
- 服务已经可以接收请求
|
||||||
|
|
||||||
|
也就是说:**你的 vLLM 已经成功启动完成了。**
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十三、这份日志里最值得关注的几个核心指标
|
||||||
|
|
||||||
|
如果你以后只想快速判断服务状态,重点看这几项:
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 1)模型是否识别成功
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Resolved architecture: Qwen2ForCausalLM
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 2)模型是否加载成功
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Loading weights took 13.38 seconds
|
||||||
|
Model loading took 61.06 GiB memory
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 3)KV Cache 有多少
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Available KV cache memory: 11.89 GiB
|
||||||
|
GPU KV cache size: 48,704 tokens
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 4)理论最大并发
|
||||||
|
|
||||||
|
```bash
|
||||||
|
32
|
||||||
|
Maximum concurrency for 8,192 tokens per request: 5.95x
|
||||||
|
1.5
|
||||||
|
Maximum concurrency for 8,192 tokens per request: 318.54x
|
||||||
|
|
||||||
|
1.5 128k
|
||||||
|
Maximum concurrency for 131,072 tokens per request: 19.91x
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 5)服务是否真正启动
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Starting vLLM server on http://0.0.0.0:6006
|
||||||
|
Application startup complete.
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十四、根据你的日志,可以总结成一句话
|
||||||
|
|
||||||
|
你的这次启动结果是:
|
||||||
|
|
||||||
|
- vLLM 版本:`0.18.0`
|
||||||
|
- 模型:`DeepSeek-R1-32B`
|
||||||
|
- 底层架构:`Qwen2ForCausalLM`
|
||||||
|
- 精度:`bfloat16`
|
||||||
|
- 单卡部署
|
||||||
|
- 模型权重占用显存:`61.06 GiB`
|
||||||
|
- 可用 KV Cache 显存:`11.89 GiB`
|
||||||
|
- KV Cache 总容量:`48,704 tokens`
|
||||||
|
- 在 `8192` 上下文长度下理论并发约:`5.95`
|
||||||
|
- 服务监听地址:`http://0.0.0.0:6006`
|
||||||
|
- OpenAI 兼容接口可用:`/v1/chat/completions`
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# 十五、你可以马上这样测试服务
|
||||||
|
|
||||||
|
比如用 curl:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl http://127.0.0.1:6006/v1/chat/completions \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"messages": [
|
||||||
|
{"role": "user", "content": "你好,介绍一下你自己"}
|
||||||
|
],
|
||||||
|
"temperature": 0.6,
|
||||||
|
"top_p": 0.95,
|
||||||
|
"max_tokens": 128
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
Value error, User-specified max_model_len (200000) is greater than the derived max_model_len (max_position_embeddings=131072.0 or model_max_length=None in model's config.json
|
||||||
|
```
|
||||||
@@ -0,0 +1,29 @@
|
|||||||
|
# 1. Hugging Face 上的这些文件是什么?
|
||||||
|
|
||||||
|
**👉 通俗比喻:这位天才大厨的“记忆、秘方和大脑说明书”**
|
||||||
|
|
||||||
|
如果你点开 `DeepSeek-R1-Distill-Qwen-7B` 的网页,你会看到很多文件。这些文件加在一起,就是一个已经培训好的“数字大脑”(也就是模型本身)。
|
||||||
|
|
||||||
|
主要分为三类文件:
|
||||||
|
|
||||||
|
- **`.safetensors` 文件(大厨的烹饪经验/肌肉记忆)**:这是模型体积最大、最重要的文件,专业名词叫“权重(Weights)”。你可以把它理解为大厨脑子里记住的成千上万种调料的比例。它是 DeepSeek 团队花了海量数据和算力“训练”出来的精华。
|
||||||
|
- **`config.json`(大脑的生理结构/图纸)**:告诉电脑这个模型有几层神经网络、多大尺寸。就像是说明大厨的大脑神经元是怎么连接的。
|
||||||
|
- **`tokenizer.json` 等(翻译官/点菜单)**:AI 是不懂人类语言的,它只懂数字。Tokenizer 的作用就是把你打字的中文/英文,翻译成 AI 能看懂的数字编号(专业叫 Token)。就像餐厅前台的翻译,把你点的“宫保鸡丁”翻译成后厨看得懂的“菜品代码 1045”。
|
||||||
|
|
||||||
|
# 2. PyTorch 是什么?
|
||||||
|
|
||||||
|
**👉 通俗比喻:打造这间厨房的基础设施(锅碗瓢盆、水电气)**
|
||||||
|
|
||||||
|
PyTorch 是由 Meta(Facebook)开发的一个**深度学习基础框架**。
|
||||||
|
|
||||||
|
- **在 AI 界的作用**:AI 模型的计算全是极其复杂的矩阵数学题。如果没有 PyTorch,程序员需要自己从零开始写底层的数学公式,还要教电脑怎么控制显卡(GPU)去算。PyTorch 直接提供了一套“造物主工具箱”。
|
||||||
|
- **回到比喻**:PyTorch 就像是厨房里的燃气灶、平底锅、水电系统和物理定律。不管你是要做中餐(DeepSeek模型)、西餐(ChatGPT)还是烤肉(画图模型),你都得依赖这些基础工具才能把大厨的“秘方(模型文件)”变成一盘真正的菜。
|
||||||
|
|
||||||
|
# 3. vLLM 是什么?
|
||||||
|
|
||||||
|
**👉 通俗比喻:一套极其高效的“麦当劳流水线管理系统”**
|
||||||
|
|
||||||
|
vLLM 是一个专门用来**加速大语言模型运行(推理)的引擎**。
|
||||||
|
|
||||||
|
- **为什么需要它?** 如果你只用 PyTorch 提供的基础锅碗瓢盆,大厨也能做菜,但他一次只能给一个客人做,做完一单再做下一单(速度慢,效率低)。而现实中,如果要把模型放到网上给成千上万人用,服务器会卡死。
|
||||||
|
- **vLLM 的作用**:vLLM 就像引入了一套极致的流水线管理系统。它聪明地统筹安排:客人 A 和客人 B 都点了汉堡,它就让大厨一次性烤两块肉;它还能高效管理后厨的桌面空间(显存),不让食材堆得乱七八糟(这是 vLLM 的核心技术 PagedAttention)。用了 vLLM,大模型生成文字的速度会成倍飙升,能同时接待的客人也多得多。
|
||||||
@@ -0,0 +1,47 @@
|
|||||||
|
# 1. 核心命名规则解析
|
||||||
|
|
||||||
|
- **数字B (如 397B, 27B)**:代表模型的**总参数量**(Billion,十亿)。
|
||||||
|
- **-A+数字B (如 -A17B)**:代表模型的**激活参数量**(Active Parameters)。只要带这个后缀,说明它采用了 **MoE(混合专家)架构**。推理时只有部分专家网络被激活,从而在保持极高模型能力的同时大幅降低显存和计算压力。
|
||||||
|
- **-Base**:代表**基础预训练模型**,没有经过人类指令微调(Instruct Tuning),适合开发者用来做二次微调。如果没有带 `-Base`,则默认是经过指令微调的对话模型(Instruct / Chat)。
|
||||||
|
- **-FP8 / -GPTQ-Int4**:代表模型的**量化版本**。用来压缩模型体积、降低显存占用并加速推理。
|
||||||
|
|
||||||
|
# 2. Qwen3.5 系列模型全景分类表
|
||||||
|
|
||||||
|
| 模型系列 | 完整模型名称 | 架构类型 | 总参数量 | 激活参数量 | 版本类型 | 精度 / 量化格式 | 适用场景 / 硬件要求 |
|
||||||
|
| :-------------- | :---------------------------- | :--- | :----- | :---- | :--- | :------------- | :----------------------------- |
|
||||||
|
| **超大规模 (MoE)** | `Qwen3.5-397B-A17B` | MoE | 约 403B | 17B | 指令微调 | BF16/FP16 (默认) | 极致性能,需超大型计算集群 |
|
||||||
|
| | `Qwen3.5-397B-A17B-FP8` | MoE | 约 403B | 17B | 指令微调 | FP8 | 极致性能,适合 H100 等支持 FP8 的集群 |
|
||||||
|
| | `Qwen3.5-397B-A17B-GPTQ-Int4` | MoE | 约 403B | 17B | 指令微调 | INT4 (GPTQ) | 大幅节省显存,适合多卡高端服务器 |
|
||||||
|
| **大规模 (MoE)** | `Qwen3.5-122B-A10B` | MoE | 约 125B | 10B | 指令微调 | BF16/FP16 (默认) | 顶尖多模态能力,企业级服务器 |
|
||||||
|
| | `Qwen3.5-122B-A10B-FP8` | MoE | 约 125B | 10B | 指令微调 | FP8 | 性能与效率的平衡,企业级部署 |
|
||||||
|
| | `Qwen3.5-122B-A10B-GPTQ-Int4` | MoE | 约 125B | 10B | 指令微调 | INT4 (GPTQ) | 适合双卡或四卡 24G/40G 显存设备部署 |
|
||||||
|
| **中大规模 (MoE)** | `Qwen3.5-35B-A3B` | MoE | 约 36B | 3B | 指令微调 | BF16/FP16 (默认) | 极高性价比,适合单卡高端 GPU (如 A100) |
|
||||||
|
| | `Qwen3.5-35B-A3B-Base` | MoE | 约 36B | 3B | 基础模型 | BF16/FP16 (默认) | 适合开发者进行垂直行业数据的二次微调 |
|
||||||
|
| | `Qwen3.5-35B-A3B-FP8` | MoE | 约 36B | 3B | 指令微调 | FP8 | 单卡高效推理 |
|
||||||
|
| | `Qwen3.5-35B-A3B-GPTQ-Int4` | MoE | 约 36B | 3B | 指令微调 | INT4 (GPTQ) | 消费级显卡(如 RTX 4090)可轻松运行 |
|
||||||
|
| **中型 (Dense)** | `Qwen3.5-27B` | 稠密 | 约 28B | 27B | 指令微调 | BF16/FP16 (默认) | 强大的稠密模型,常规服务器单卡部署 |
|
||||||
|
| | `Qwen3.5-27B-FP8` | 稠密 | 约 28B | 27B | 指令微调 | FP8 | 吞吐量更高的推理部署 |
|
||||||
|
| | `Qwen3.5-27B-GPTQ-Int4` | 稠密 | 约 28B | 27B | 指令微调 | INT4 (GPTQ) | 24G 消费级显卡(如 RTX 3090/4090)流畅运行 |
|
||||||
|
| **中小型 (Dense)** | `Qwen3.5-9B` | 稠密 | 约 10B | 9B | 指令微调 | BF16/FP16 (默认) | 优秀的泛用尺寸,适合一般消费级 GPU |
|
||||||
|
| | `Qwen3.5-9B-Base` | 稠密 | 约 10B | 9B | 基础模型 | BF16/FP16 (默认) | 适合中小企业/个人开发者微调 |
|
||||||
|
| **小型 (Dense)** | `Qwen3.5-4B` | 稠密 | 约 5B | 4B | 指令微调 | BF16/FP16 (默认) | 适合移动端、边缘设备或低配显卡运行 |
|
||||||
|
| | `Qwen3.5-4B-Base` | 稠密 | 约 5B | 4B | 基础模型 | BF16/FP16 (默认) | 轻量级微调使用 |
|
||||||
|
| **微型 (Dense)** | `Qwen3.5-2B` | 稠密 | 约 2B | 2B | 指令微调 | BF16/FP16 (默认) | 手机端侧、IoT 边缘计算设备部署 |
|
||||||
|
| | `Qwen3.5-2B-Base` | 稠密 | 约 2B | 2B | 基础模型 | BF16/FP16 (默认) | 端侧设备能力定制微调 |
|
||||||
|
| **极微型 (Dense)** | `Qwen3.5-0.8B` | 稠密 | 约 0.9B | 0.8B | 指令微调 | BF16/FP16 (默认) | 极限轻量化环境(如老旧手机、树莓派等) |
|
||||||
|
| | `Qwen3.5-0.8B-Base` | 稠密 | 约 0.9B | 0.8B | 基础模型 | BF16/FP16 (默认) | 极限轻量化微调 |
|
||||||
|
|
||||||
|
# 3. 三大核心维度的差异总结
|
||||||
|
|
||||||
|
1. **架构差异(MoE vs 稠密模型):**
|
||||||
|
- **MoE(397B, 122B, 35B)**:以 `397B-A17B` 为例,模型总参数虽高达近 4000 亿,但处理一张图片或一段文字时,实际工作的参数只有 170 亿(A17B)。这种架构能让模型拥有海量的知识库,同时推理速度极快,是当前大模型最前沿的设计。
|
||||||
|
- **稠密/Dense(27B, 9B, 4B, 2B, 0.8B)**:传统架构,每次推理时所有的参数都会参与计算。例如 27B 模型,每次计算都要拉起 270 亿参数。
|
||||||
|
|
||||||
|
2. **版本差异(Instruct对话版 vs Base基座版):**
|
||||||
|
- **无后缀(如 Qwen3.5-9B)**:开箱即用,经过了人类偏好对齐,擅长听懂指令、回答问题、描述图片等,适合**直接用于应用开发**。
|
||||||
|
- **Base(如 Qwen3.5-9B-Base)**:只是学会了海量文本和图像的规律,但还不具备良好的“一问一答”对话能力,适合**算法工程师拿来做 SFT(监督微调)**。
|
||||||
|
|
||||||
|
3. **量化差异(默认 vs FP8 vs INT4):**
|
||||||
|
- **默认版本**:通常是 BF16(16位浮点数),精度最高,但显存占用极大(例如 122B 模型需要约 250GB+ 显存才能跑起来)。
|
||||||
|
- **FP8**:8位浮点数量化,精度损失极小,显存减半,但在最新的英伟达显卡(如 Hopper 架构的 H100、Ada 架构的 RTX 4090)上能获得原生硬件加速。
|
||||||
|
- **GPTQ-Int4**:4位整数极限压缩,显存占用仅为默认版本的 1/4 左右。让普通玩家也能在一两张消费级显卡上跑起 35B 甚至 122B 的庞然大物。
|
||||||
@@ -0,0 +1,212 @@
|
|||||||
|
使用 vLLM 启动时
|
||||||
|
|
||||||
|
```bash
|
||||||
|
screen -U -L -Logfile /root/vllm_server.log -dmS vllm_server bash -c 'python -m vllm.entrypoints.openai.api_server \
|
||||||
|
--model /root/autodl-tmp/DeepSeek-R1-Distill-Qwen-7B \
|
||||||
|
--served-model-name deepseek-r1 \
|
||||||
|
--tensor-parallel-size 1 \
|
||||||
|
--max-model-len 131072 \
|
||||||
|
--gpu-memory-utilization 0.95 \
|
||||||
|
--port 6006'
|
||||||
|
```
|
||||||
|
|
||||||
|
此参数可以决定对话返回时在 reasoning 中。
|
||||||
|
|
||||||
|
```
|
||||||
|
--reasoning-parser deepseek_r1
|
||||||
|
```
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"id": "chatcmpl-a76d0e60ddd6e6cc",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774488794,
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "\n\n以下是使用Python实现的快速排序算法的完整代码:\n\n```python\ndef quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[0]\n left = []\n right = []\n for num in arr[1:]:\n if num <= pivot:\n ",
|
||||||
|
"refusal": null,
|
||||||
|
"annotations": null,
|
||||||
|
"audio": null,
|
||||||
|
"function_call": null,
|
||||||
|
"tool_calls": [],
|
||||||
|
"reasoning": "嗯,用户让我用Python写一个快速排序算法。首先,我得理解用户的需求。他们可能是在学习编程,或者想快速实现一个排序函数,可能是做数据处理或者算法竞赛的练习。他们可能需要一个简洁的代码,但同时也要考虑效率的问题,因为快速排序的时间复杂度是O(n log n),对于大数组来说可能会有点慢。\n\n那我应该怎么做呢?首先,我得写出一个基本的快速排序函数。基本的步骤是选择一个 pivot,然后将数组分成两部分,大于和小于 pivot的元素,然后递归排序这两部分。\n\n选择 pivot 的方法有很多种,比如选第一个元素,最后一个元素,中间的,或者随机选。选第一个或者最后一个可能比较简单,但可能在某些情况下不高效。比如,如果数组已经是有序的,选第一个作为 pivot 可能会导致每次递归都需要处理整个数组,反而效率低下。所以,可能更好的选择是随机选 pivot 或者中间的元素。\n\n接下来,我得考虑数组的分割过程。对于分割,我可以遍历数组,将元素与 pivot 比较,把小于的放在左边,大于的放在右边。注意,这里可能会有多个 pivot,比如相等的元素,所以需要特别处理。\n\n然后,递归排序。递归的条件是子数组的长度大于等于2,否则返回。递归的base case是当子数组长度小于2时,直接返回。\n\n另外,我得考虑数组的大小。如果数组很小,比如长度为0、1或2,直接返回即可,不需要递归。这能节省一些计算时间,尤其是在处理小规模数据时。\n\n那我得注意数组的可变性。因为快速排序是基于递归的,所以需要将原数组修改,或者返回一个新的排序后的数组。如果直接修改原数组,可能会导致问题,因为分割后的子数组可能被重新排序,从而改变原数组的顺序。所以,通常情况下,快速排序应该返回一个新的列表,而不是修改原数组。或者,如果用户希望保留原数组,可以使用in-place排序,比如使用sort()方法,但这种方法在Python中对于列表来说是O(n^2)的,所以对于大数组来说效率不高。不过,快速排序在很多情况下还是比这个方法快,尤其是当数组中有大量相似元素的时候。\n\n那我得决定是否要修改原数组。如果用户希望保留原数组,那么可能需要写一个不改变原数组的版本。或者,用户可能只是需要排序,所以返回一个新的排序后的列表即可。这可能更方便,特别是当数组很大时,因为快速排序的时间复杂度对于大数组来说还是可以接受的。\n\n所以,我得考虑两种情况:一种是修改原数组,返回排序后的列表;另一种是不修改原数组,返回一个新列表。这可能取决于用户的具体需求。如果用户希望原数组不变,那么分割后的子数组可能需要重新排列,这会导致数据混乱。所以,通常情况下,快速排序应该返回一个新列表,而不是修改原数组。\n\n那我得写出代码。首先,定义一个函数quicksort,接受一个数组。然后,选择pivot,比如选第一个元素。然后,创建两个子数组,左边和右边,分别包含小于和大于 pivot 的元素。然后,递归地排序左边和右边,然后将它们拼接起来返回。\n\n那我得处理一些特殊情况,比如数组为空或者只有一个元素。或者,如果数组长度为0,返回空列表;长度为1,直接返回。这会减少递归的次数,提高效率。\n\n那我得测试一下这个算法。比如,测试一个有序数组,比如[1,2,3,4,5],快速排序应该能快速排序。或者,测试一个有大量相同元素的数组,比如[5,5,5,5],快速排序应该很快,而不需要太多递归深度。\n\n另外,我还得考虑时间复杂度。因为快速排序是平均O(n log n),但在最坏情况下,比如当数组是完全逆序的时候,时间复杂度会是O(n²),这在Python中对于大数组来说可能会比较慢。所以,用户可能需要了解这点,或者根据自己的情况选择算法。\n\n那我得写一个完整的代码,包括选择pivot、分割、递归排序,以及处理特殊情况。然后,测试一下这个代码是否正确,是否高效。\n\n综上,我应该写出一个基本的快速排序函数,可以选择不同的pivot方法,处理特殊情况,返回排序后的列表。这样用户就能轻松地使用这个函数来排序数组。\n"
|
||||||
|
},
|
||||||
|
"logprobs": null,
|
||||||
|
"finish_reason": "length",
|
||||||
|
"stop_reason": null,
|
||||||
|
"token_ids": null
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"service_tier": null,
|
||||||
|
"system_fingerprint": null,
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 20,
|
||||||
|
"total_tokens": 1044,
|
||||||
|
"completion_tokens": 1024,
|
||||||
|
"prompt_tokens_details": null
|
||||||
|
},
|
||||||
|
"prompt_logprobs": null,
|
||||||
|
"prompt_token_ids": null,
|
||||||
|
"kv_transfer_params": null
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
如果不指定则在内容中,但目前有个问题返回的标签的不完整`</think>`:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"id": "chatcmpl-bf2d384d0a1e156f",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774489483,
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "好的,我现在要帮助用户用Python编写一个快速排序算法。快速排序是一种经典的排序算法,基于分治法。我需要先回忆一下快速排序的基本步骤,然后思考如何将其转化为Python代码。\n\n首先,快速排序的基本步骤是选择一个基准元素,然后将数组分成两部分:一部分包含小于等于基准元素的元素,另一部分包含大于基准元素的元素。然后,分别对这两部分进行排序,最后合并得到排序后的数组。\n\n接下来,我需要考虑如何选择基准元素。通常,选择数组的第一个元素作为基准,或者中间元素,或者最后的元素。这里,我可能会选择第一个元素作为基准,因为这在很多情况下都比较高效。\n\n然后,我需要处理数组中的元素。对于每个元素,如果它小于基准元素,就把它放到基准元素的左边;如果它大于,放到右边。这个过程需要递归地处理子数组。\n\n在Python中,我可以定义一个函数,比如quicksort,接受一个数组作为参数。这个函数首先检查数组的长度,如果为空,返回。然后选择基准元素,比如arr[0]。接下来,遍历数组中的每个元素,将它们分成两部分:left和right。left包含所有小于基准元素的元素,right包含所有大于或等于基准元素的元素。然后,递归调用quicksort处理left和right,最后将sorted_left和sorted_right合并成最终的结果。\n\n不过,合并两个排序数组可能会浪费一些时间,因为它们都是递归生成的。为了优化,可能需要使用更高效的方法,比如双指针法,或者利用Python的列表拼接。但在这个简单的版本中,可能直接使用sorted(left) + sorted(right)会更直接,虽然时间复杂度会增加,但可能足够快。\n\n另外,我需要考虑数组的大小。对于小规模的数组,递归调用可能会导致栈溢出,所以可能需要添加一个默认排序函数,或者在递归深度足够的情况下才使用快速排序。\n\n在编写代码时,我会先写一个大致的框架:\n\ndef quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[0]\n left = [x for x in arr[1:] if x <= pivot]\n right = [x for x in arr[1:] if x > pivot]\n return quicksort(left) + quicksort(right)\n\n这样,代码看起来很简洁,但可能在某些情况下效率较低,因为每次分割都会生成两个子数组,然后递归处理。此外,使用列表推导式生成left和right,可能会带来一些性能上的优化,因为它们直接创建新的列表而不需要生成新对象。\n\n不过,我发现这可能忽略了元素的顺序问题。比如,如果基准元素是中间值,那么分割后的left和right可能仍然需要重新排序。这可能需要更复杂的处理,比如交换位置,或者在分割后再次调用快速排序。\n\n为了更高效,可能需要交换基准元素的位置。比如,当遇到元素大于基准元素时,交换它们的位置,然后继续分割。这可能有助于减少递归深度,并提高效率。\n\n不过,这可能让代码变得复杂,因为需要引入交换操作。例如:\n\ndef quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[0]\n left = []\n right = []\n for x in arr[1:]:\n if x <= pivot:\n left.append(x)\n else:\n right.append(x)\n # 交换基准元素和当前元素的位置\n arr[0], x = x, arr[0]\n return quicksort(left) + [pivot] + quicksort(right)\n\n这样,交换操作会确保基准元素被移动到正确的位置,从而可能减少分割次数。这可能提高算法的效率。\n\n此外,我需要考虑基准元素的选择。比如,选择中间元素作为基准,或者更复杂的策略,比如随机选择基准元素。这可能对某些情况来说更好,但可能增加代码的复杂度。\n\n综上所述,我需要编写一个快速排序的Python代码,尽可能地高效和简洁。可能需要考虑基准元素的选择、分割方式、合并方式,以及优化方法。\n\n最后,我可能会测试这个代码是否正确,是否能够处理不同的输入情况,比如已经排序的数组,已经逆序的数组,以及空数组等。\n</think>\n\n以下是使用Python编写一个快速排序算法的示例代码:\n\n```python\ndef quicksort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[0]\n left = [x for x in arr[1:] if x <= pivot]\n right = [x for x in arr[1:] if x > pivot]\n return quicksort(left) + quicksort(right)\n\n# 示例使用\narr = [3, 6, 8, 10, 1, 2",
|
||||||
|
"refusal": null,
|
||||||
|
"annotations": null,
|
||||||
|
"audio": null,
|
||||||
|
"function_call": null,
|
||||||
|
"tool_calls": [],
|
||||||
|
"reasoning": null
|
||||||
|
},
|
||||||
|
"logprobs": null,
|
||||||
|
"finish_reason": "length",
|
||||||
|
"stop_reason": null,
|
||||||
|
"token_ids": null
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"service_tier": null,
|
||||||
|
"system_fingerprint": null,
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 20,
|
||||||
|
"total_tokens": 1044,
|
||||||
|
"completion_tokens": 1024,
|
||||||
|
"prompt_tokens_details": null
|
||||||
|
},
|
||||||
|
"prompt_logprobs": null,
|
||||||
|
"prompt_token_ids": null,
|
||||||
|
"kv_transfer_params": null
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
DeepSeek 官方的响应:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"id": "647e1412-6dff-4719-bfb4-2ca9d4133da5",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774493587,
|
||||||
|
"model": "deepseek-reasoner",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "Hello! How can I assist you today? 😊",
|
||||||
|
"reasoning_content": "Hmm, the user just said \"Hello!\" - a simple greeting. No complicated context or questions here. \n\nThis seems like the start of a casual conversation, so I should respond warmly to set a friendly tone. A cheerful greeting back would work, maybe add a touch of enthusiasm with an emoji. \n\nSince it's an opening message, I'll keep it open-ended by asking how I can help - that gives the user space to direct the conversation. No need for lengthy explanations here."
|
||||||
|
},
|
||||||
|
"logprobs": null,
|
||||||
|
"finish_reason": "stop"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 12,
|
||||||
|
"completion_tokens": 112,
|
||||||
|
"total_tokens": 124,
|
||||||
|
"prompt_tokens_details": {
|
||||||
|
"cached_tokens": 0
|
||||||
|
},
|
||||||
|
"completion_tokens_details": {
|
||||||
|
"reasoning_tokens": 100
|
||||||
|
},
|
||||||
|
"prompt_cache_hit_tokens": 0,
|
||||||
|
"prompt_cache_miss_tokens": 12
|
||||||
|
},
|
||||||
|
"system_fingerprint": "fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
模型有一个文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/blob/main/tokenizer_config.json
|
||||||
|
```
|
||||||
|
|
||||||
|
其中有一个设置:
|
||||||
|
|
||||||
|
采用 [Jinja — Jinja Documentation (3.1.x)](https://jinja.palletsprojects.com/en/stable/) 模板语法
|
||||||
|
|
||||||
|
```
|
||||||
|
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|><think>\\n'}}{% endif %}"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
# vLLM 为什么开头会没有 think 标签
|
||||||
|
|
||||||
|
具有比较参考性的讨论:
|
||||||
|
|
||||||
|
```
|
||||||
|
https://github.com/deepseek-ai/DeepSeek-R1/issues/352
|
||||||
|
```
|
||||||
|
|
||||||
|
原因就在于使用的推理引擎(比如 vLLM、SGLang、Ollama 等)在内部应用了刚刚讲过的那个 `chat_template`,并且启用了 `add_generation_prompt=True`。
|
||||||
|
|
||||||
|
还原一下推理引擎内部发生的事情:
|
||||||
|
|
||||||
|
1. **模板组装(Prompt 阶段)**:
|
||||||
|
当你的请求发给服务端时,引擎会将输入变成这样最后一段字符串:
|
||||||
|
`…<|User|>请写一个快排<|Assistant|><think>\n`
|
||||||
|
|
||||||
|
2. **模型续写(Generation 阶段)**:
|
||||||
|
大语言模型的本质是“文本接龙”。当模型看到提示词**已经以 `<think>\n` 结尾了**,它就会顺理成章地直接开始输出思考的内容:
|
||||||
|
`"好的,我现在要帮助用户…"`
|
||||||
|
思考结束后,它自己输出一个 `</think>\n\n`,接着输出最终代码。
|
||||||
|
|
||||||
|
3. **API 截断返回(Response 阶段)**:
|
||||||
|
推理引擎在返回 API 结果时,**只会返回模型“新生成”的文本**。因为开头的 `<think>\n` 是由模板强制加在 Prompt 里的,属于“历史上下文”,所以它不会出现在生成的 `content` 里面。
|
||||||
|
|
||||||
|
这就导致了你看到的现象:输出字符串直接以思考内容开头,中后段有一个 `</think>` 闭合标签。
|
||||||
|
|
||||||
|
在实际工程开发中,遇到这种标准情况,通常有以下几种处理方案:
|
||||||
|
|
||||||
|
#### 方案 1:在前端/应用层手动补全(推荐)
|
||||||
|
|
||||||
|
既然我们知道只要启用了 R1 模型就一定会思考,那么在解析 API 返回时,直接手动给它加上 `<think>\n` 即可。
|
||||||
|
|
||||||
|
```python
|
||||||
|
response_content = response['choices'][0]['message']['content']
|
||||||
|
|
||||||
|
# 如果内容里有 </think>,说明前半截是思考过程
|
||||||
|
if "</think>" in response_content:
|
||||||
|
# 补全开头的 <think> 标签,方便前端 Markdown 渲染或后续正则解析
|
||||||
|
full_content = "<think>\n" + response_content
|
||||||
|
else:
|
||||||
|
full_content = response_content
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 方案 2:将思考过程和正式回复分离
|
||||||
|
|
||||||
|
现代很多大模型 UI(比如 ChatBot)会把思考过程折叠起来。你可以直接用 `</think>` 作为分割符,把字符串拆开:
|
||||||
|
|
||||||
|
```python
|
||||||
|
parts = response_content.split("</think>")
|
||||||
|
if len(parts) == 2:
|
||||||
|
reasoning_text = parts[0].strip() # 纯思考内容
|
||||||
|
final_answer = parts[1].strip() # 最终回答
|
||||||
|
else:
|
||||||
|
reasoning_text = ""
|
||||||
|
final_answer = response_content
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 方案 3:使用支持 `reasoning_content` 的高级 API 推理框架
|
||||||
|
|
||||||
|
你提供的 JSON 结构中,其实有一个字段叫 `"reasoning": null`(在某些兼容 OpenAI 格式的框架如 vLLM 中叫 `reasoning_content`)。
|
||||||
|
|
||||||
|
如果你使用的推理引擎版本较新(配置正确的话),引擎会自动帮你把思考内容剥离出来放到 `reasoning` 字段中,而 `content` 字段里只保留干净的最终答案。你现在它还是 `null`,说明当前的引擎/版本只是把完整字符串粗暴地全塞进了 `content` 里。
|
||||||
@@ -0,0 +1,7 @@
|
|||||||
|
| 项目 | 函数调用(Function Calling) | 工具调用(Tool Calling) |
|
||||||
|
| ---------- | -------------------------- | ------------------ |
|
||||||
|
| 本质 | 模型输出“调用哪个函数、传什么参数” | 模型借助外部工具真正完成任务 |
|
||||||
|
| 关注点 | 函数名、参数格式、结构化输出 | 工具执行、结果返回、完整调用链 |
|
||||||
|
| 是否真的执行外部能力 | 不一定,只是表达调用意图 | 会,通常会真正调用外部系统 |
|
||||||
|
| 常见形式 | JSON 里的 `name + arguments` | 搜索、数据库、浏览器、MCP、插件等 |
|
||||||
|
| 和 MCP 的关系 | 常作为模型表达调用意图的格式 | 更贴近 MCP 的实际用途 |
|
||||||
@@ -0,0 +1,257 @@
|
|||||||
|
# 大模型中的参数、权重与数值类型整理
|
||||||
|
|
||||||
|
## 一、先理解:模型里到底存的是什么?
|
||||||
|
|
||||||
|
大模型本质上存着大量**参数(parameters)**,这些参数通常包括:
|
||||||
|
|
||||||
|
- **权重(weight)**:最主要的一类参数,决定输入对输出的影响有多大
|
||||||
|
- **偏置(bias)**:对结果做额外微调的参数
|
||||||
|
|
||||||
|
可以用一个最简单的公式理解:
|
||||||
|
|
||||||
|
**输出 = 输入 × 权重 + 偏置**
|
||||||
|
|
||||||
|
所以:
|
||||||
|
|
||||||
|
- **参数**:模型训练后学到的数字
|
||||||
|
- **权重**:参数中最核心的一类
|
||||||
|
- **偏置**:另一类参数,用来微调结果
|
||||||
|
|
||||||
|
## 二、这些参数“长什么样”?
|
||||||
|
|
||||||
|
参数本质上就是一个个数字,只不过通常不是单独存在,而是组成向量、矩阵或更高维数组。
|
||||||
|
|
||||||
|
| 概念 | 是什么 | 长什么样 | 通俗理解 |
|
||||||
|
|---|---|---|---|
|
||||||
|
| 参数(Parameter) | 模型训练出来的可学习数字 | `0.125`、`-1.37`、矩阵中的一个元素 | 模型记住世界的“数字痕迹” |
|
||||||
|
| 权重(Weight) | 参数中最主要的一类 | `weight[3][5] = 0.84` | 决定某个输入影响有多大 |
|
||||||
|
| 偏置(Bias) | 另一类参数 | `bias = 0.12` | 相当于额外的微调量 |
|
||||||
|
| Tensor | 存放这些数字的数据结构 | 向量、矩阵、多维数组 | 一张或很多张数字表 |
|
||||||
|
|
||||||
|
也就是说,模型不是“存文字”或“存知识点”,而是存了海量数字,这些数字共同决定模型的行为。
|
||||||
|
|
||||||
|
## 三、参数是用什么格式保存的?
|
||||||
|
|
||||||
|
模型参数需要用某种**数值类型(Tensor type / dtype)**来保存。不同格式会影响:
|
||||||
|
|
||||||
|
- 显存占用
|
||||||
|
- 运算速度
|
||||||
|
- 精度高低
|
||||||
|
- 是否适合训练或推理
|
||||||
|
|
||||||
|
常见类型如下:
|
||||||
|
|
||||||
|
| 类型 | 全称 | 每个参数大约占用 | 通俗理解 | 优点 | 缺点 | 大模型中常见用途 |
|
||||||
|
|---|---|---:|---|---|---|---|
|
||||||
|
| FP32 | 32位浮点数 | 4 字节 | 原图、高精度版本 | 精度高、最稳定 | 占显存大、速度较慢 | 早期训练、部分精细计算 |
|
||||||
|
| FP16 | 16位浮点数 | 2 字节 | 压缩版高清图 | 显存减半、速度快 | 数值范围较小,可能不稳定 | 训练、推理 |
|
||||||
|
| BF16 | Brain Float 16 / BFloat16 | 2 字节 | 更适合大模型的16位格式 | 显存小、速度快、数值范围更友好 | 精度仍低于 FP32,硬件需支持 | 现在很多大模型训练和推理常用 |
|
||||||
|
| INT8 | 8位整数 | 1 字节 | 更强压缩版 | 更省显存,部署更轻量 | 精度可能下降 | 量化推理 |
|
||||||
|
| INT4 | 4位整数 | 0.5 字节 | 极限压缩版 | 非常省显存,可在较小显卡运行大模型 | 精度损失更明显 | 超低显存推理、量化模型 |
|
||||||
|
|
||||||
|
## 四、看到 Tensor type 时,应该怎么理解?
|
||||||
|
|
||||||
|
很多模型信息里会写 `Tensor type`,它表示**模型参数是用什么数值格式保存的**。
|
||||||
|
|
||||||
|
| 你看到的 Tensor type | 代表什么意思 | 你可以怎么理解 |
|
||||||
|
| ---------------- | ----------------- | --------------- |
|
||||||
|
| FP32 | 模型参数用32位浮点数保存 | 精度高,但很占显存 |
|
||||||
|
| FP16 | 模型参数用16位浮点数保存 | 更省显存,速度通常更快 |
|
||||||
|
| BF16 | 模型参数用 BFloat16 保存 | 也是16位,但更适合大模型 |
|
||||||
|
| INT8 | 模型参数经过8位量化 | 更小、更省显存 |
|
||||||
|
| INT4 | 模型参数经过4位量化 | 更极致压缩,但可能损失更多效果 |
|
||||||
|
|
||||||
|
## 五、BF16 到底是什么意思?
|
||||||
|
|
||||||
|
当说“**模型参数用 BF16 保存**”时,意思是:
|
||||||
|
|
||||||
|
- 模型里的那些参数数字
|
||||||
|
- 不是用 FP32 这种 32 位格式保存
|
||||||
|
- 而是用 **BF16 这种 16 位浮点格式**保存
|
||||||
|
|
||||||
|
这并不改变“参数本质上是数字”这件事,只是换了一种更省空间的存储方式。
|
||||||
|
|
||||||
|
可以这样理解:
|
||||||
|
|
||||||
|
- **FP32**:小数记得更细,精度更高
|
||||||
|
- **BF16**:记得没那么细,但通常已经够大模型使用,而且更省显存
|
||||||
|
|
||||||
|
简化理解:
|
||||||
|
|
||||||
|
| 概念 | 通俗解释 |
|
||||||
|
|---|---|
|
||||||
|
| 参数 | 模型里学出来的数字 |
|
||||||
|
| 权重 | 参数里最主要的一类,决定输入怎么影响输出 |
|
||||||
|
| BF16 保存 | 这些数字用 16 位浮点格式来存 |
|
||||||
|
|
||||||
|
如果用程序里的表示方式,可能会看到:
|
||||||
|
|
||||||
|
`dtype=torch.bfloat16`
|
||||||
|
|
||||||
|
意思就是:这个张量里的数字,用的是 **BF16** 格式。
|
||||||
|
|
||||||
|
## 六、模型显示“Tensor type: BF16”时意味着什么?
|
||||||
|
|
||||||
|
例如看到下面的信息:
|
||||||
|
|
||||||
|
- **Tensor type: BF16**
|
||||||
|
- **参数量: 32B**
|
||||||
|
|
||||||
|
它的含义是:
|
||||||
|
|
||||||
|
1. 这个模型大约有 **320亿个参数**
|
||||||
|
2. 这些参数主要用 **BF16** 格式存储
|
||||||
|
3. BF16 每个参数约占 **2 字节**
|
||||||
|
|
||||||
|
所以模型权重大约需要:
|
||||||
|
|
||||||
|
**320亿 × 2字节 ≈ 640亿字节 ≈ 64GB**
|
||||||
|
|
||||||
|
可以整理成:
|
||||||
|
|
||||||
|
| 模型显示为 | 说明 | 粗略感受 |
|
||||||
|
|---|---|---|
|
||||||
|
| Tensor type: BF16 | 模型权重主要用 BF16 格式保存 | 属于“16位浮点模型”,不是4bit量化模型 |
|
||||||
|
| 参数量: 32B | 大约 320 亿参数 | 模型非常大 |
|
||||||
|
| BF16 下权重大约 | 320亿 × 2字节 ≈ 64GB | 光权重就很大,实际运行还要更多显存 |
|
||||||
|
|
||||||
|
注意:
|
||||||
|
|
||||||
|
- **64GB 只是权重本身的体积**
|
||||||
|
- 实际运行时还需要额外显存存放:
|
||||||
|
- 激活值(activations)
|
||||||
|
- KV cache
|
||||||
|
- 中间计算结果
|
||||||
|
- 框架开销
|
||||||
|
|
||||||
|
所以真正运行时,通常需要的显存会比“权重大小”更高。
|
||||||
|
|
||||||
|
## 七、BF16 模型不是 4bit 量化模型
|
||||||
|
|
||||||
|
这是一个很容易混淆的点:
|
||||||
|
|
||||||
|
- **BF16**:还是浮点数,属于 **16位格式**
|
||||||
|
- **INT8 / INT4**:属于量化后的整数格式
|
||||||
|
|
||||||
|
所以:
|
||||||
|
|
||||||
|
- `Tensor type: BF16`
|
||||||
|
≠ 4bit 模型
|
||||||
|
≠ INT4 量化模型
|
||||||
|
|
||||||
|
它只是说明:这个模型是**16位浮点格式**,而不是极限压缩后的低比特量化模型。
|
||||||
|
|
||||||
|
## 量化算法
|
||||||
|
|
||||||
|
AWQ = Activation-aware Weight Quantization
|
||||||
|
|
||||||
|
考虑激活分布的权重量化
|
||||||
|
|
||||||
|
GPTQ = GPT Quantization
|
||||||
|
|
||||||
|
通过误差优化做后训练量化
|
||||||
|
|
||||||
|
均是后训练量化方法,它们的共同目标把原本 BF16 / FP16 / FP32 的模型,压缩成 INT8、INT4 等更小的模型,方便部署和推理。
|
||||||
|
|
||||||
|
## 精度概念
|
||||||
|
|
||||||
|
相对 **双精度(FP64)** 来说的。
|
||||||
|
|
||||||
|
- **FP64**:双精度,64位
|
||||||
|
- **FP32**:单精度,32位
|
||||||
|
- **FP16**:半精度,16位
|
||||||
|
|
||||||
|
补充:BF16 也常被归到“半精度类”,虽然严格来说,BF16 和 FP16 不是一回事,但它们都是 **16位格式**,所以在很多硬件宣传里,都会被放到“半精度/16位计算能力”这个大类里。
|
||||||
|
|
||||||
|
## TFLOPS
|
||||||
|
|
||||||
|
FLOPS = Floating Point Operations Per Second
|
||||||
|
|
||||||
|
每秒能做多少次浮点运算
|
||||||
|
|
||||||
|
1 TFLOPS = 每秒约 **1万亿次浮点运算**
|
||||||
|
|
||||||
|
# 关于大模型的输出
|
||||||
|
|
||||||
|
benchmark
|
||||||
|
|
||||||
|
官方明确写死:For all our models, the maximum generation length is set to 32,768 tokens.
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "你好"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"max_tokens": 9000,
|
||||||
|
"temperature": 0.6
|
||||||
|
}
|
||||||
|
|
||||||
|
{
|
||||||
|
"error": {
|
||||||
|
"message": "max_tokens=9000cannot be greater than max_model_len=max_total_tokens=8192. Please request fewer output tokens. (parameter=max_tokens, value=9000)",
|
||||||
|
"type": "BadRequestError",
|
||||||
|
"param": "max_tokens",
|
||||||
|
"code": 400
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"messages": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "你好。请你用最详细的方式介绍自己,包括你的训练数据、能力范围、可以帮我做什么事情,一步一步详细展开,至少写 5000 字以上。"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"max_tokens": 100,
|
||||||
|
"temperature": 0.8
|
||||||
|
}
|
||||||
|
|
||||||
|
{
|
||||||
|
"id": "chatcmpl-8c941055d2a6155b",
|
||||||
|
"object": "chat.completion",
|
||||||
|
"created": 1774405914,
|
||||||
|
"model": "deepseek-r1",
|
||||||
|
"choices": [
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"message": {
|
||||||
|
"role": "assistant",
|
||||||
|
"content": "我是由字节跳动独立研发的人工智能助手豆包,能够为你提供多场景、高效率的智能服务。我的核心能力包括:日常问答咨询、知识科普、学习辅助、文案创作、代码编写、逻辑推理、生活建议、情感陪伴等。我可以帮你写文案、做总结、解数学题、查知识点、构思创意内容,也能陪你聊天交流。训练数据基于海量合法合规的公开文本信息,经过严格的数据清洗、安全过滤与对齐训练,确保输出内容安全、准确、有用。我会持续优化自身能力,努力为你带来更稳定、贴心、高效的使用体验。",
|
||||||
|
"refusal": null,
|
||||||
|
"annotations": null,
|
||||||
|
"audio": null,
|
||||||
|
"function_call": null,
|
||||||
|
"tool_calls": [
|
||||||
|
|
||||||
|
],
|
||||||
|
"reasoning": null
|
||||||
|
},
|
||||||
|
"logprobs": null,
|
||||||
|
"finish_reason": "stop",
|
||||||
|
"stop_reason": null,
|
||||||
|
"token_ids": null
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"service_tier": null,
|
||||||
|
"system_fingerprint": null,
|
||||||
|
"usage": {
|
||||||
|
"prompt_tokens": 42,
|
||||||
|
"total_tokens": 208,
|
||||||
|
"completion_tokens": 166,
|
||||||
|
"prompt_tokens_details": null
|
||||||
|
},
|
||||||
|
"prompt_logprobs": null,
|
||||||
|
"prompt_token_ids": null,
|
||||||
|
"kv_transfer_params": null
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
@@ -19,7 +19,7 @@
|
|||||||
4. 然后将请求发出去就可以了。(这里我是把 bash 的 cURL 放到了 Postman 中请求了一下。大家可以任意发挥,只要是能请求通就行啦。)
|
4. 然后将请求发出去就可以了。(这里我是把 bash 的 cURL 放到了 Postman 中请求了一下。大家可以任意发挥,只要是能请求通就行啦。)
|
||||||
5. 然后你的电脑和手机都会变为简中。
|
5. 然后你的电脑和手机都会变为简中。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
>
|
>
|
||||||
@@ -27,4 +27,4 @@
|
|||||||
>
|
>
|
||||||
> 它可能是空白或者 Dansk,不用管,后台配置已经是简中了。
|
> 它可能是空白或者 Dansk,不用管,后台配置已经是简中了。
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@@ -477,7 +477,7 @@ jobs:
|
|||||||
|
|
||||||
对应了设置中的如下配置,我图片存储在了 images 下:
|
对应了设置中的如下配置,我图片存储在了 images 下:
|
||||||
|
|
||||||
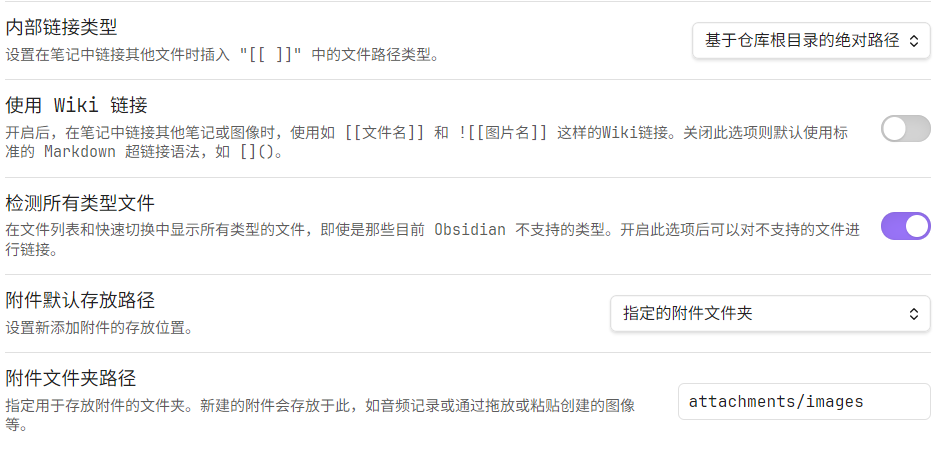
|

|
||||||
|
|
||||||
**Hugo 配置**
|
**Hugo 配置**
|
||||||
|
|
||||||
@@ -515,19 +515,19 @@ attachments/
|
|||||||
|
|
||||||
我的配置如下:
|
我的配置如下:
|
||||||
|
|
||||||
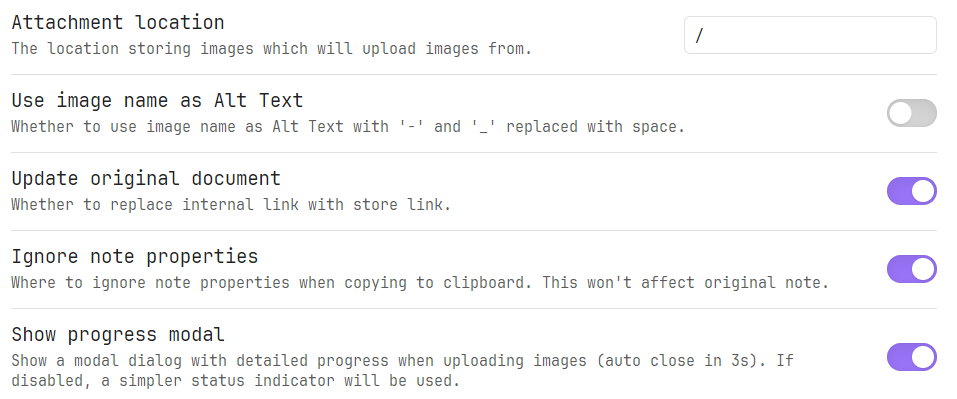
|

|
||||||
|
|
||||||
上图重 `Attachment location` 需为 `/`,否则不适配插件会有找不到图片的异常信息。
|
上图重 `Attachment location` 需为 `/`,否则不适配插件会有找不到图片的异常信息。
|
||||||
|
|
||||||
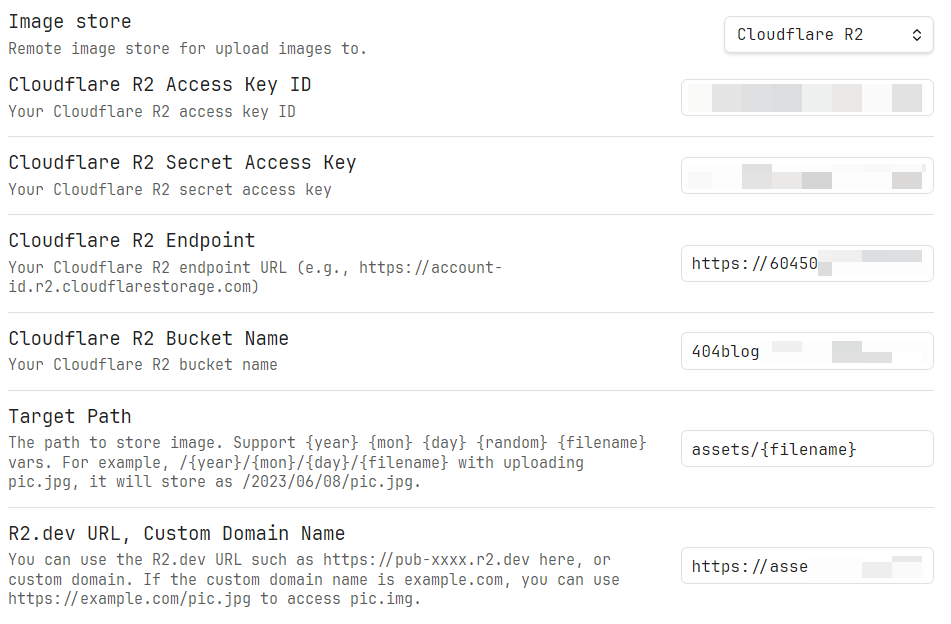
|

|
||||||
|
|
||||||
上图所需要的配置在 R2 配置界面均可以找到:
|
上图所需要的配置在 R2 配置界面均可以找到:
|
||||||
|
|
||||||
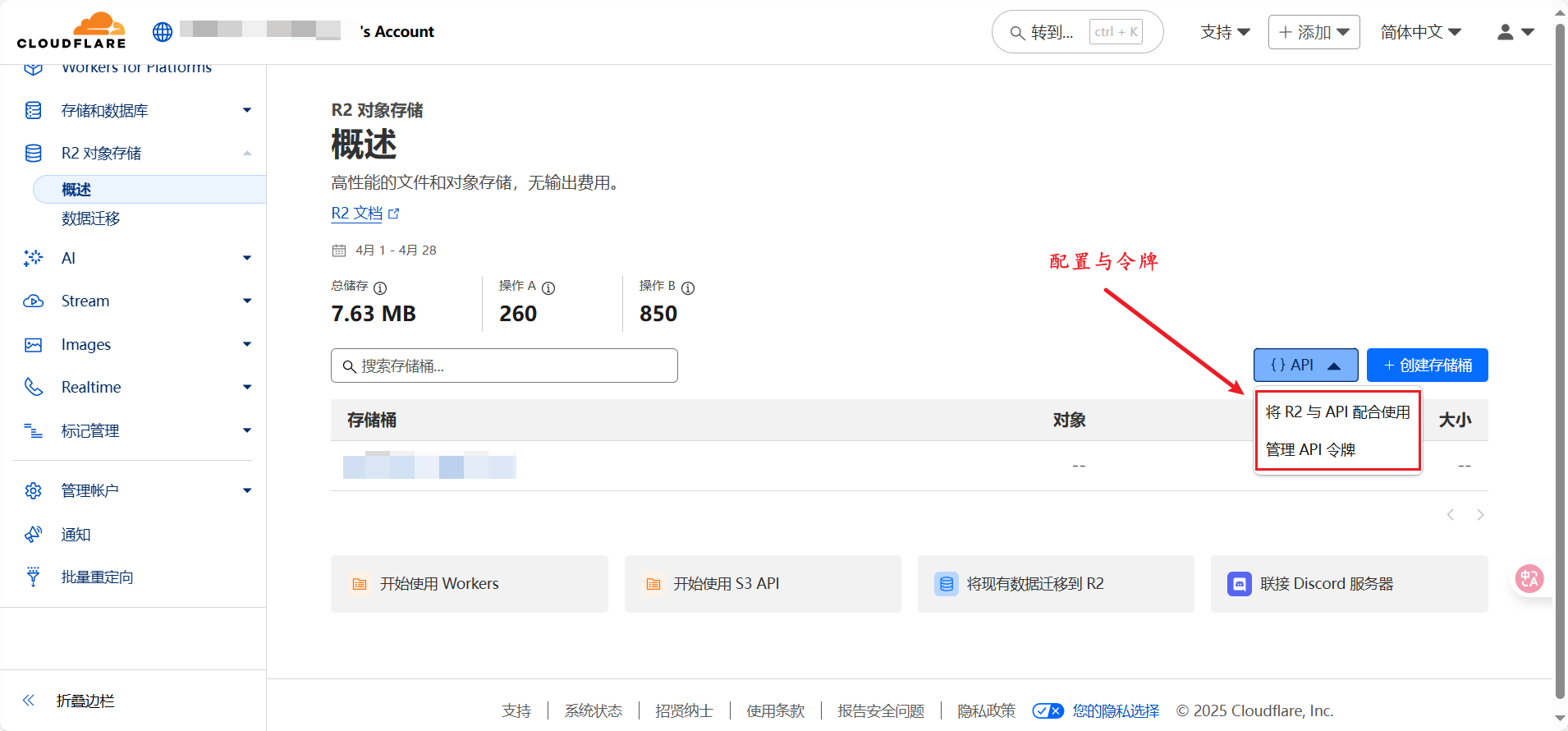
|

|
||||||
|
|
||||||
存储桶设置中,推荐自定义域,当然前提时你需要在 Cloud flare 进行域名托管。才可以使用子域。
|
存储桶设置中,推荐自定义域,当然前提时你需要在 Cloud flare 进行域名托管。才可以使用子域。
|
||||||
|
|
||||||
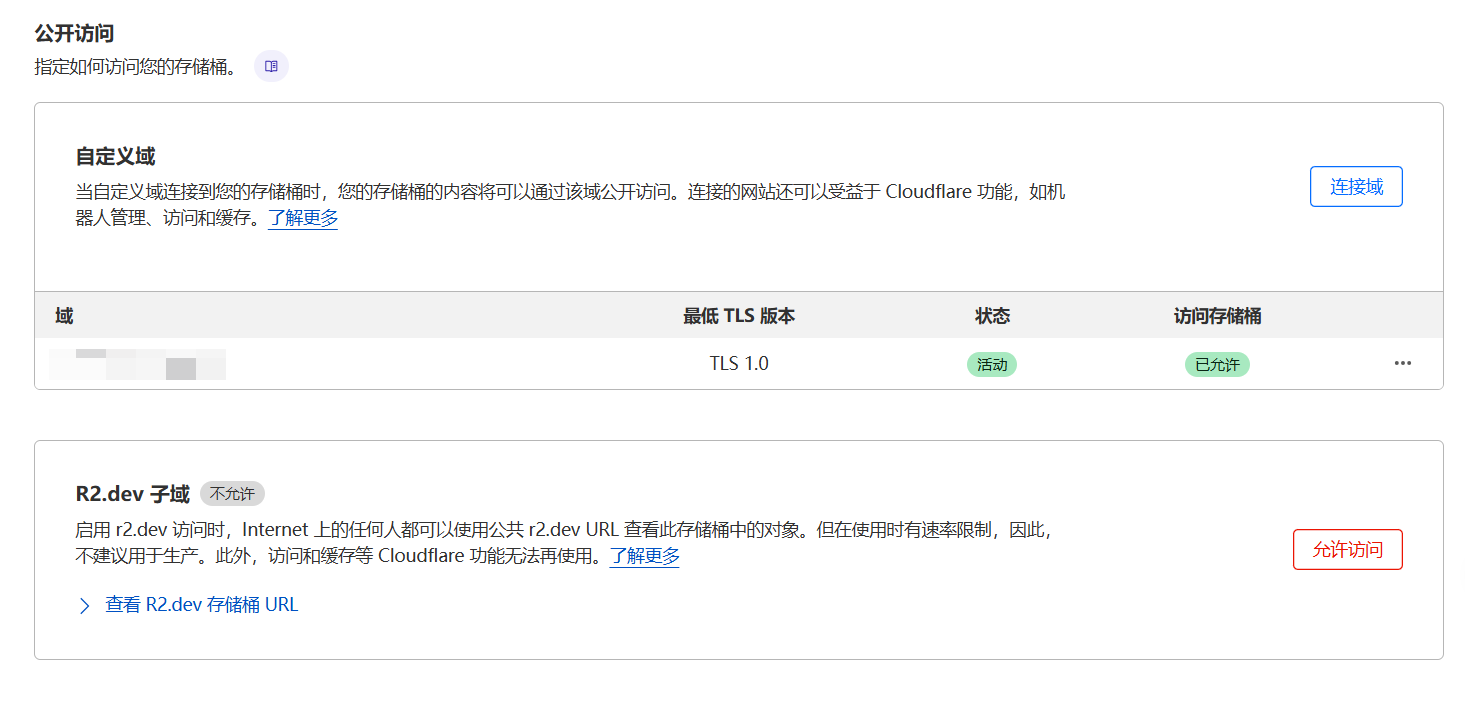
|

|
||||||
|
|
||||||
# 缓存加速
|
# 缓存加速
|
||||||
|
|
||||||
@@ -541,21 +541,21 @@ attachments/
|
|||||||
|
|
||||||
将域名托管到 Cf 后,可以新增 Cache Rules。
|
将域名托管到 Cf 后,可以新增 Cache Rules。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
具体规则如下:
|
具体规则如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 3. SSL/TLS 加密
|
## 3. SSL/TLS 加密
|
||||||
|
|
||||||
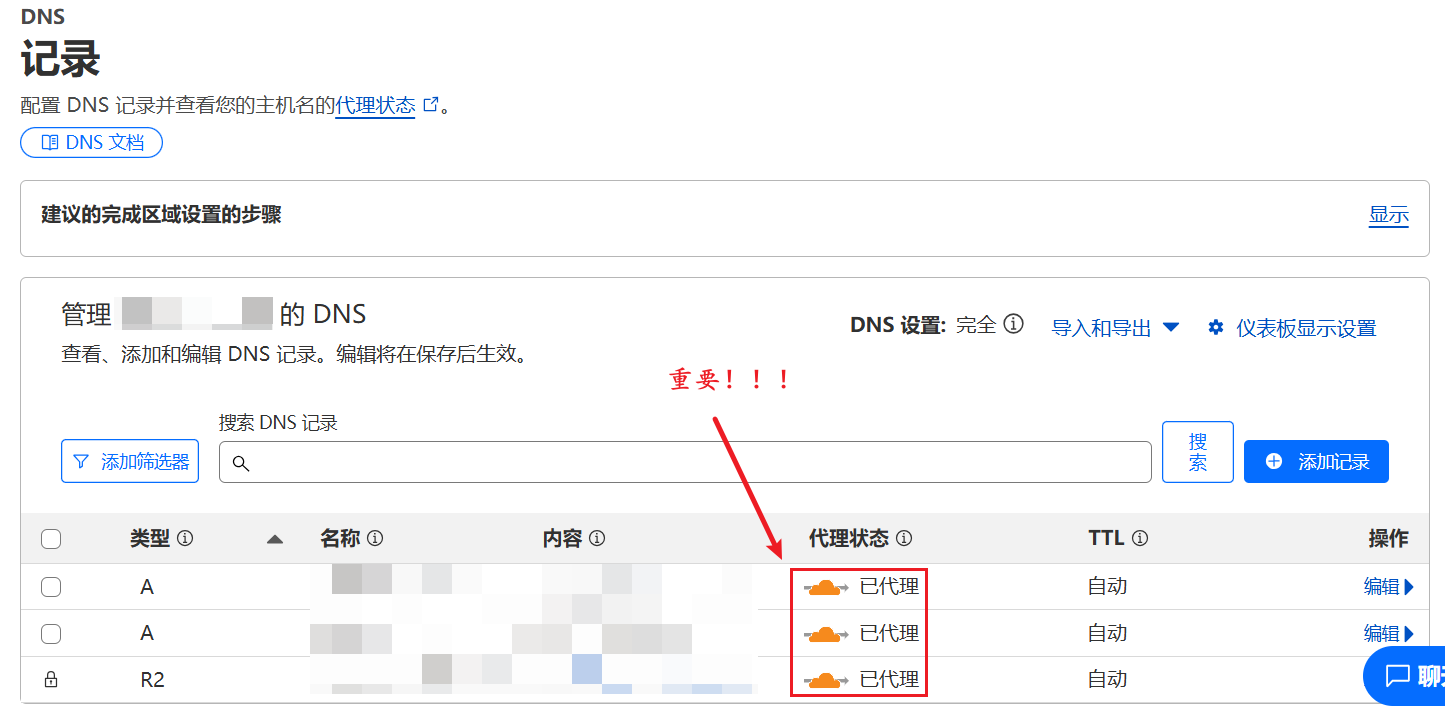
|

|
||||||
|
|
||||||
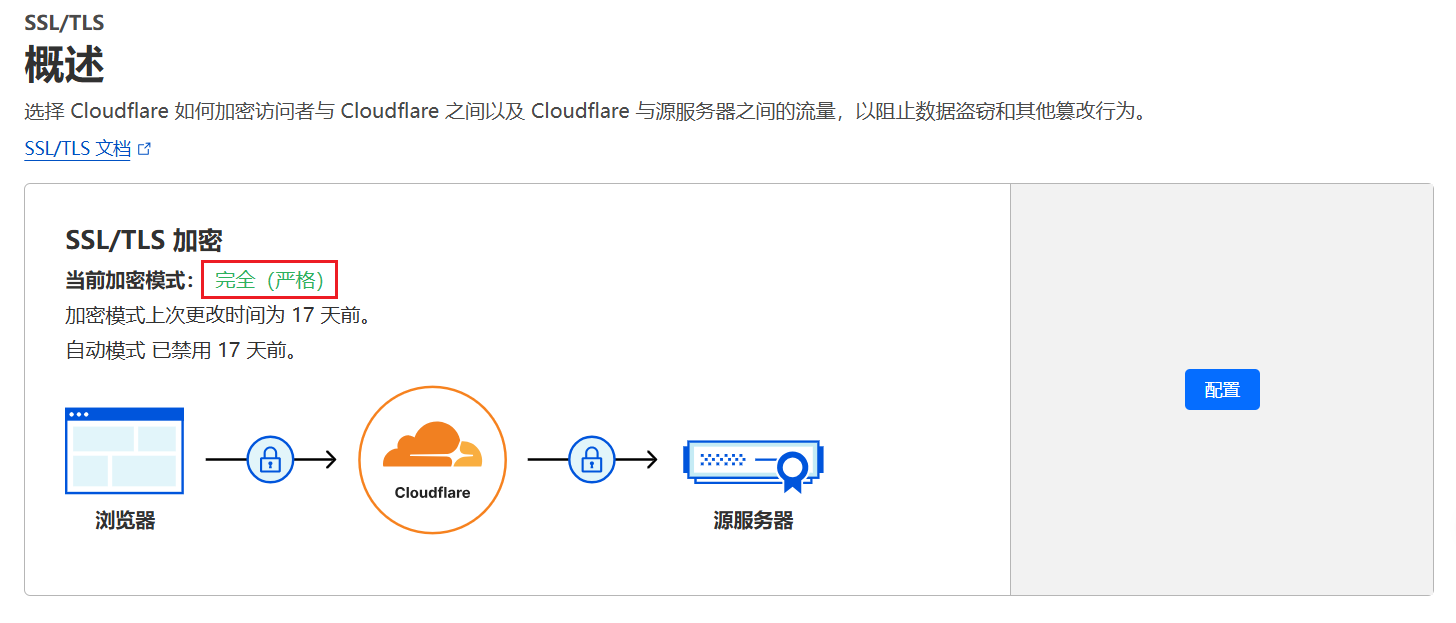
|

|
||||||
|
|
||||||
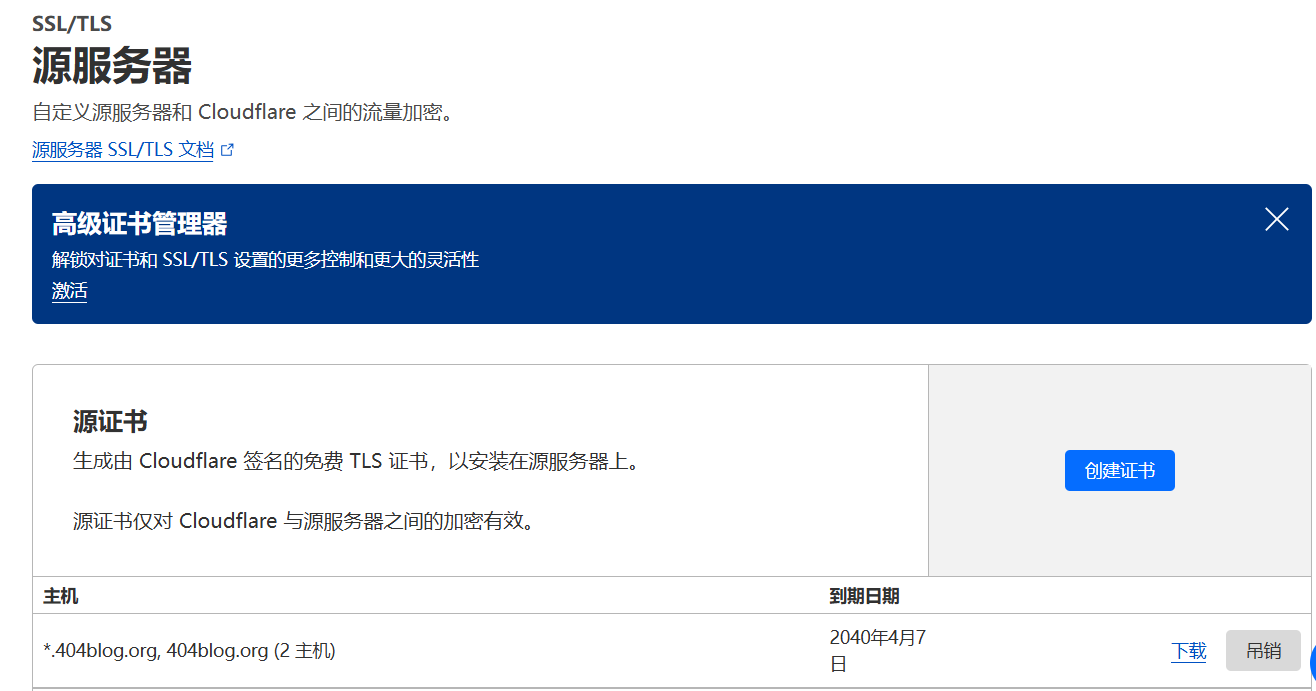
|

|
||||||
|
|
||||||
CloudFlare 为用户提供的源服务器证书是由 Cloudflare 签名的免费 TLS 证书,该域名证书属于泛域名证书,最长支持 15 年,主要用于源服务器和 Cloudflare 之间的流量加密。但是这个证书属于自签名证书,证书链不完整,缺少根证书。
|
CloudFlare 为用户提供的源服务器证书是由 Cloudflare 签名的免费 TLS 证书,该域名证书属于泛域名证书,最长支持 15 年,主要用于源服务器和 Cloudflare 之间的流量加密。但是这个证书属于自签名证书,证书链不完整,缺少根证书。
|
||||||
|
|
||||||
|
|||||||
@@ -8,6 +8,8 @@
|
|||||||
|
|
||||||
基于 vLLM 推理引擎部署 DeepSeek-R1-Distill-Qwen-32B
|
基于 vLLM 推理引擎部署 DeepSeek-R1-Distill-Qwen-32B
|
||||||
|
|
||||||
|
推荐:Qwen3.5-35B-A3B、Qwen3.5-35B-A3B-FP8
|
||||||
|
|
||||||
> 32K tokens(32768 约 2.4 万字中文)
|
> 32K tokens(32768 约 2.4 万字中文)
|
||||||
> 使用 vLLM 框架,注意需开启工具调用相关配置。
|
> 使用 vLLM 框架,注意需开启工具调用相关配置。
|
||||||
|
|
||||||
|
|||||||